

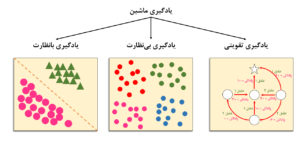
یادگیری تقویتی در مقایسه با روشهای دیگر
یادگیری تقویتی یک رویکرد متمایز در یادگیری ماشین است که به طور قابل توجهی با دو رویکرد اصلی دیگر تفاوت دارد.
یادگیری با نظارت در مقابل یادگیری تقویتی
در یادگیری بانظارت، یک متخصص انسانی مجموعه دادهها را برچسبگذاری کرده است، به این معنی که پاسخهای صحیح ارائه شدهاند. به عنوان مثال، مجموعه دادهها میتواند شامل تصاویری از خودروهای مختلف باشد که متخصص هر خودرو را با نام سازنده آن برچسبگذاری کرده است.
دادهها به همراه پاسخهای صحیح به ماشین ارائه میشوند و ماشین یاد میگیرد که آنها را تکرار کند.
در یادگیری بانظارت، عامل یادگیرنده یک ناظر دارد که مانند معلم، پاسخهای صحیح را ارائه میدهد. از طریق آموزش با این مجموعه دادههای برچسبگذاری شده، عامل بازخورد دریافت میکند و میآموزد که چگونه دادههای جدید و ناشناخته (مانند تصاویر خودرو) را در آینده طبقهبندی کند.
در یادگیری تقویتی، دادهها بخشی از ورودی نیستند بلکه از طریق تعامل با محیط جمعآوری میشوند. بهجای اینکه سیستم را از پیش در مورد اینکه کدام اقدامات برای انجام یک وظیفه بهینه هستند مطلع کند، یادگیری تقویتی از پاداشها و جریمهها استفاده میکند. بنابراین، عامل پس از انجام هر عمل، بازخورد دریافت میکند.
یادگیری بدون نظارت در مقابل یادگیری تقویتی
یادگیری بدون نظارت با دادههای بدون برچسب سر و کار دارد و در اینجا بازخوردی وجود ندارد. هدف این است که مجموعه دادهها را کاوش کرده و شباهتها، تفاوتها یا خوشهها را در دادههای ورودی پیدا کنیم بدون اینکه از قبل اطلاعاتی درباره خروجی مورد انتظار داشته باشیم.
دادهها بدون پاسخهای صحیح به ماشین ارائه میشوند و ماشین باید بهطور مستقل الگوها را پیدا کند.
از سوی دیگر، یادگیری تقویتی شامل کاوش در محیط است، نه در مجموعه دادهها، و هدف نهایی متفاوت است: عامل تلاش میکند تا بهترین اقدام ممکن را در موقعیت معین انجام دهد تا پاداش کل را به حداکثر برساند. بدون مجموعه دادههای آموزشی، مشکل یادگیری تقویتی توسط اقدامات خود عامل و با ورودی از محیط حل میشود.
جدول زیر تفاوت بین یادگیری تحت نظارت، یادگیری بدون نظارت و یادگیری تقویتی را نشان می دهد :
| یادگیری با نظارت | یادگیری بی نظارت | یادگیری تقویتی | |
|---|---|---|---|
| دادههای ورودی | برچسبگذاری شده: «پاسخ صحیح» در آن گنجانده شده است. | برچسبگذاری نشده: «پاسخ صحیح» مشخص نشده است. | دادهها بخشی از ورودی نیستند، بلکه از طریق آزمون و خطا جمعآوری میشوند. |
| مسئلهای که باید حل شود. | برای انجام پیشبینی (مانند ارزش آینده یک سهام) یا طبقهبندی (مانند شناسایی درست ایمیلهای اسپم) استفاده میشود. | برای کشف و شناسایی الگوها، ساختارها یا روابط در مجموعه دادههای بزرگ استفاده میشود (مثلاً افرادی که محصول A را سفارش میدهند، محصول B را نیز سفارش میدهند) | برای حل مسائل مبتنی بر پاداش استفاده میشود (مثلاً یک بازی ویدئویی). |
| راه حل | ورودی را به خروجی متصل میکند. | تشابهات و تفاوتها در دادههای ورودی را پیدا کرده و آنها را به کلاسهای مختلف طبقهبندی میکند. | تعیین میکند که کدام وضعیتها و اقدامات بیشترین پاداش تجمعی کلی را برای عامل به حداکثر میرساند. |
| وظایف عمومی | طبقه بندی ، رگرسیون | خوشهبندی، کاهش ابعاد، یادگیری وابستگی | کشف و بهرهبرداری |
| مثال | تشخیص تصویر، پیشبینی بازار سهام | تقسیمبندی مشتریان، توصیه محصولات | بازیهای رایانهای، جاروبرقیهای رباتیک |
| نظارت | بلی | بلی | خیر |
| بازخورد | بله. مجموعه صحیح اقدامها ارائه شده است. | خیر | بله، از طریق پاداشها و تنبیهها (پاداشهای مثبت و منفی). |
نحوه اجرای یادگیریتقویتی
پیادهسازی یادگیری تقویتی شامل چندین مرحله است؛ از تعریف محیط گرفته تا آموزش عامل و ارزیابی عملکرد آن.
1.تعریف محیط (Define the Environment)
اولین قدم در پیادهسازی یادگیری تقویتی، تعریف محیطی است که عامل در آن فعالیت خواهد کرد. این محیط باید شامل حالات، اقدامات، احتمالات انتقال و ساختار پاداش باشد.
مثال : فرض کنید یک محیط دو بعدی داریم که شامل یک اتاق است. در این اتاق، تعدادی سکه و موانع قرار داده شدهاند. ربات ما در این اتاق حرکت میکند و هدفش جمعآوری سکهها است. اتاق شامل حالات(States) است که موقعیتهای مختلف ربات در محیط را نشان میدهد (مثلاً ربات در مختصات [x,y]) اقدامات (Actions) شامل حرکات ربات به سمت بالا، پایین، چپ یا راست است. وقتی ربات به سکه برسد، پاداش (Reward) مثلاً ۱۰ امتیاز میگیرد و اگر به مانع برخورد کند، ۵- امتیاز دریافت میکند.
2.تعریف عامل (Define the Agent)
عامل همان ربات است که باید تصمیم بگیرد چه کاری انجام دهد. ما به او یک استراتژی میدهیم که در هر موقعیت مشخص کند چه تصمیمی بگیرد تا به هدفش (جمعآوری سکهها) برسد.
مثال : عامل در اینجا ربات است. ما باید برای ربات یک سیاست (Policy) تعریف کنیم؛ یعنی راهبردی که ربات را هدایت میکند تا بهترین اقدامات را در هر وضعیت انتخاب کند. برای مثال، سیاست میتواند این باشد که ربات همیشه سعی کند به سمتی برود که سکه بیشتری در آنجا وجود دارد. همچنین، تابع ارزش (Value Function) به ما کمک میکند تا ارزیابی کنیم هر وضعیت چقدر برای ربات ارزشمند است؛ بهعنوان مثال، اینکه ربات در نزدیکی یک سکه باشد چقدر مطلوب است.
3.مقداردهی اولیه به عامل (Initialize the Agent)
تعاریف مختلف
سیاست عامل و توابع ارزش را مقداردهی اولیه کنید. این معمولاً شامل تنظیم وزنهای اولیه برای یک شبکه عصبی یا مقداردهی اولیه Q-values برای الگوریتم Q-Learning است.
مانند زمانی که تازه میخواهیم به ربات آموزش بدهیم، در ابتدا او نمیداند چه کاری درست است. بنابراین باید با یک سیاست و مقادیر اولیه ساده شروع کنیم.
مثال : در ابتدا، ربات چیزی از محیط نمیداند. بنابراین باید سیاست اولیه و تابع ارزش آن را مقداردهی کنیم. فرض کنید برای شروع، ربات هیچ تجربهای ندارد و همه احتمالات و ارزشها را برابر در نظر میگیرد. بهعنوان مثال، اگر ربات از Q-Learning استفاده کند، مقدار اولیه Q-values (ارزش اقدامات مختلف در حالات مختلف) برابر با صفر است.
4.آموزش عامل (Training the Agent)
ربات با حرکت در محیط، تجربه کسب میکند. بهعنوان مثال، اگر به سمت دیوار برود، یاد میگیرد که این حرکت اشتباه است و اگر به سمت سکه برود، متوجه میشود که این کار درست است. با تمرین بیشتر، ربات بهتر و بهتر میشود.
اکتشاف و بهرهبرداری: ربات باید گاهی اوقات حرکات جدیدی را امتحان کند (اکتشاف) تا راههای جدیدی برای پیدا کردن سکهها بیابد. اما وقتی مطمئن شد که یک راه خوب است، از آن راه استفاده میکند (بهرهبرداری).
مثال : ربات در محیط شروع به حرکت میکند. در هر لحظه یک اقدام انجام میدهد (مثلاً به سمت راست میرود). سپس میبیند چه اتفاقی میافتد (آیا سکه پیدا کرده یا با مانع برخورد کرده است). بر اساس این تجربه، پاداش یا جریمه دریافت میکند و از این اطلاعات برای بهروزرسانی سیاست و تابع ارزش خود استفاده میکند. به تدریج، ربات یاد میگیرد که کدام حرکتها بهتر است.
5.عملکرد عامل را ارزیابی کنید (Evaluate the Agent)
بعد از اینکه به ربات آموزش دادیم، باید ببینیم چقدر خوب یاد گرفته است. با مشاهده عملکردش در محیط میتوانیم ارزیابی کنیم که آیا تصمیماتش خوب هستند یا خیر.
بازبینی بصری: میتوانیم بازی ربات را مشاهده کنیم تا ببینیم که آیا واقعاً یاد گرفته است یا خیر. بهعنوان مثال، میتوانیم بررسی کنیم که آیا هنوز با موانع برخورد میکند یا بهسرعت به سمت سکهها میرود.
مثال : بعد از اینکه ربات برای مدتی آموزش دید، باید ببینیم که چقدر خوب یاد گرفته است. بهعنوان مثال، ربات را در چندین مرحله از بازی قرار میدهیم و بررسی میکنیم که آیا میتواند بیشترین سکهها را جمعآوری کند یا خیر. معیار پاداش تجمعی (مجموع پاداشهایی که ربات دریافت کرده است) نشان میدهد که چقدر خوب کار کرده است.
6.تنظیم فراپارامترها (Hyperparameter Tuning)
مانند این است که به ربات بگوییم با چه سرعتی یاد بگیرد. اگر خیلی سریع یا خیلی کند یاد بگیرد، ممکن است عملکردش به درستی پیش نرود. بنابراین، باید پارامترهای آموزشی را بهدقت تنظیم کنیم.
فراپارامترها شامل نرخ یادگیری (چقدر سریع یاد بگیرد) ، ضریب تخفیف (چقدر به پاداشهای آینده اهمیت دهد) و نرخ اکتشاف هستند.
بهعنوان مثال، اگر نرخ یادگیری خیلی بالا باشد، ممکن است ربات حرکات اشتباه را سریع یاد بگیرد و کارهای بدتری انجام دهد. بنابراین، باید با تنظیمات مختلف این پارامترها، عملکرد ربات را بهینه کنیم.
7.پیادهسازی عامل (Deploying the Agent)
حالا که ربات خوب یاد گرفته است، او را در دنیای واقعی یا یک محیط واقعی قرار میدهیم تا کارش را انجام دهد. اگر محیط تغییر کند، ربات باید همچنان یاد بگیرد و خود را تطبیق دهد.
مثال : وقتی مطمئن شدیم که ربات بهخوبی یاد گرفته است، او را در محیط واقعی قرار میدهیم. بهعنوان مثال، میتوانیم او را در یک بازی واقعی یا در یک ربات واقعی که در یک کارخانه کار میکند، قرار دهیم. همچنین باید مراقب باشیم که اگر محیط تغییر کرد، ربات بتواند با آن سازگار شود و به یادگیری ادامه دهد.
ترتیبی که هوشینو برای خواندن مطالب یادگیری تقویتی به شما پیشنهاد میکند:
2.یادگیری تقویتی بخش دوم
10.الگوریتم Q-Learning بخش سوم
13. تفاوت بین Q-Learning و SARSA