زنجیره مارکوف چیست ؟
زنجیره مارکوف یک مدل تصادفی است که احتمال وقوع دنبالهای از رویدادها را بر اساس رویداد قبلی تعیین میکند. این زنجیرهها به ما کمک میکنند تا رفتار سیستمها را در طول زمان پیشبینی کنیم. این مدل که توسط آندری مارکوف ایجاد شده، از ریاضیات برای پیشبینی احتمال رخدادهای آینده بر اساس آخرین وضعیت استفاده میکند. یکی از مثالهای کاربردی زنجیره مارکوف، پیشبینی کلمه بعدی در جیمیل توسط گوگل است که بر اساس ورودیهای قبلی کاربر انجام میشود. همچنین، الگوریتم PageRank گوگل که رتبهبندی لینکها در نتایج جستجو را تعیین میکند، نمونه دیگری از استفاده از زنجیره مارکوف است. این مدل بهویژه در صنایعی که با دادههای توالیدار سر و کار دارند، بسیار رایج و مفید است و به ما امکان میدهد با استفاده از مشاهدات گذشته، رویدادهای آینده را تخمین بزنیم.
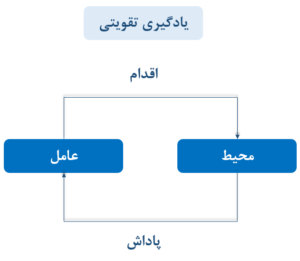
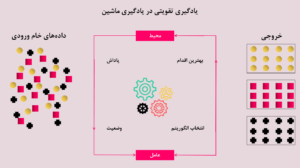
زنجیره مارکوف ،یک سیگنال وضعیت است که تمام اطلاعات موردنیاز از گذشته را در خود حفظ کرده و تنها بر اساس وضعیت فعلی میتواند آینده را پیشبینی کند، مارکوف یا دارای خاصیت مارکوف گفته میشود. این خاصیت به این معناست که وضعیت آینده تنها به وضعیت فعلی وابسته است و نیازی به دانستن تاریخچه دقیق رویدادهای گذشته ندارد. فرآیند تصمیمگیری مارکوف (MDP) یک چارچوب قدرتمند برای حل مسائل یادگیری تقویتی است که به عامل کمک میکند تا در محیطهای نامطمئن، بهترین تصمیمها را اتخاذ کند و پاداش کلی خود را بهینه سازد. این چارچوب با فراهم کردن ساختاری برای مدلسازی تصمیمات بر اساس وضعیتهای مختلف و پیشبینی نتایج آنها، عامل را قادر میسازد تا به طور مؤثر در محیطهای پیچیده عمل کند.
هدف اصلی فرآیند مارکوف، شناسایی احتمال انتقال از یک حالت به حالت دیگر است. این فرآیند به ما کمک میکند تا تغییرات در سیستمهای مختلف را مدلسازی کنیم و پیشبینی کنیم که در آینده چه حالتی ممکن است رخ دهد. به عبارت ساده تر :
در زنجیره مارکوف در یادگیری تقویتی، هدف اصلی این است که با سادهسازی مسئله، پیشبینی آینده را آسانتر و سریعتر کنیم، بدون نیاز به جمعآوری اطلاعات زیاد از گذشته باشد.
از اهداف این مدل:
- آینده فقط به وضعیت فعلی وابسته است.
- اطلاعات گذشتههای دورتر اهمیت ندارد.
- مدلسازی و پیشبینی را سادهتر میکند.
اصل زنجیره مارکوف
یکی از جذابیتهای اصلی زنجیره مارکوف این است که وضعیت آینده یک متغیر تصادفی تنها به وضعیت فعلی آن بستگی دارد. به عبارت دیگر، پیشبینی آینده تنها به وضعیت حاضر وابسته است و به تاریخچه گذشته نیازی ندارد. یک تعریف غیررسمی از متغیر تصادفی این است که آن را بهعنوان متغیری توصیف میکنیم که مقادیر آن به نتایج رخدادهای تصادفی وابسته است.
سه مفهوم اصلی که نشان میدهد زنجیره ما مارکوف است:
1.خاصیت مارکوف (Markov Property) :
این خاصیت بیان میکند که برای پیشبینی وضعیت آینده، تنها وضعیت کنونی کافی است و نیازی به دانستن تاریخچهی وضعیتها نیست. به عبارت دیگر :
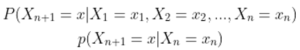
این یعنی احتمال اینکه ![]() گام x باشد فقط به مرحله n بستگی دارد نه توالی کامل مراحل قبل از n .
گام x باشد فقط به مرحله n بستگی دارد نه توالی کامل مراحل قبل از n .
برای مثال یک رستوران سه نوع غذا درست میکند : پیتزا ، همبرگر و هات داگ
فرض کنید این رستوران روز اول همبرگر و روز دوم پیتزا و روز سوم بازهم پیتزا درست میکند . حالا این احتمال چقدر است که این رستوران در روز چهارم هات داگ درست بکند ؟
![]()
برای اینکه بفهمیم چقدر احتمال دارد که فردا هات داگ درست بکند باید به روز قبلش نگاه بکنیم :
![]()
این بدان معناست که احتمال وقوع وضعیت آینده تنها به وضعیت کنونی بستگی دارد.
2.حالتهای قطعی (Discrete States) :
در زنجیرههای مارکوف، حالتها معمولاً مجموعهای از وضعیتهای گسسته هستند که سیستم میتواند در آنها قرار بگیرد. هر حالت دارای احتمال مشخصی برای انتقال به حالتهای دیگر در زمان بعدی است. این احتمالها نشاندهنده چگونگی تغییر وضعیت سیستم در زمان هستند.
این حالتها معمولاً در قالب یک گراف یا ماتریس نمایش داده میشوند. در گراف، هر حالت بهعنوان یک گره (نود) و هر انتقال احتمالی بین حالتها بهعنوان یال (لبه) نمایش داده میشود. در ماتریس، هر سطر و ستون نمایانگر حالتها هستند و هر عنصر ماتریس، احتمال انتقال از یک حالت به حالت دیگر را نشان میدهد.
این روشهای نمایش به ما کمک میکنند تا بهراحتی ساختار زنجیره مارکوف را درک کنیم و محاسبات مربوط به احتمال انتقال بین حالتها را انجام دهیم.
3.انتقال احتمال (Transition Probability) :
هر زنجیره مارکوف دارای یک ماتریس انتقال است که مقادیر آن نشاندهندهی احتمال انتقال از یک حالت به حالت دیگر است.
مجموع هر ردیف در این ماتریس باید برابر با ۱ باشد، زیرا تمام احتمالات انتقال از یک حالت به حالتهای دیگر باید جمعاً برابر با یک باشند. به عبارت دیگر، اگر یک حالت خاص را در نظر بگیریم، احتمال اینکه سیستم در مرحله بعد به یکی از حالتهای ممکن منتقل شود، باید ۱ باشد.
این سه مفهوم، اساس فهم و تحلیل زنجیرههای مارکوف را تشکیل میدهند .
ویژگی اصلی زنجیره مارکوف چیست ؟
- همانطور که پیشتر اشاره شد، فرآیند مارکوف یک فرآیند تصادفی است که دارای ویژگی بدون حافظه (memoryless) میباشد. در ریاضیات، اصطلاح «بدون حافظه» به خاصیتی در توزیعهای احتمالی اشاره دارد. بهطور کلی، این ویژگی به سناریوهایی مربوط میشود که زمان وقوع یک رویداد خاص، وابسته به مدت زمانی که تاکنون سپری شده است، نیست. به عبارت دیگر، وقتی یک مدل خاصیت بدون حافظه دارد، به این معناست که مدل «فراموش کرده» است که در کدام وضعیت
تصویر1-بدون حافظه سیستم قرار دارد. بنابراین، حالتهای قبلی فرآیند تأثیری بر احتمالات نخواهند داشت.
- ویژگی اصلی یک فرآیند مارکوف همین خاصیت بدون حافظه است. پیشبینیهای مرتبط با فرآیند مارکوف، مشروط به وضعیت فعلی آن هستند و مستقل از حالتهای گذشته و آیندهاند.
- این ویژگی بدون حافظه در مدل مارکوف میتواند هم یک مزیت و هم یک محدودیت باشد. بهعنوان مثال، تصور کنید میخواهید کلمات یا جملاتی را بر اساس متنی که قبلاً وارد کردهاید پیشبینی کنید — دقیقاً مانند کاری که گوگل برای جیمیل انجام میدهد.
- اما نقطه ضعف این روش این است که نمیتوانید متنی را پیشبینی کنید که بر اساس زمینهای از حالت قبلی مدل باشد. این یک مشکل رایج در پردازش زبان طبیعی (Natural Language Processing یا NLP) است و بسیاری از مدلها با این چالش مواجهاند.
اجزای زنجیرهی مارکوف
وضعیتها، وضعیتهای ممکن یک سیستم هستند. هر زنجیره مارکوف مجموعهای از وضعیتها دارد. به عنوان مثال، فرض کنید ما یک زنجیره مارکوف برای توصیف حالتی از یک ماشین بازی داریم. وضعیتها میتوانند شامل موارد زیر باشند:
- ماشین خاموش
- ماشین روشن
- ماشین در حال کار
اقداماتی که میتوان در هر حالت انجام داد.
3.انتقالهای حالت (State Transitions)
انتقال به معنای حرکت از یک وضعیت به وضعیت دیگر است. هر انتقال دارای یک احتمال مشخص است که نشان میدهد چقدر احتمال دارد که سیستم از یک وضعیت به وضعیت دیگر تغییر کند. توصیف میکند که اگر یک عمل انجام شود، احتمال انتقال از یک حالت به حالت دیگر چگونه است.
برای مثال، اگر ماشین روشن باشد، احتمال اینکه خاموش شود 30% و احتمال اینکه در حال کار باشد 70% است.
4.ماتریس انتقال (Transition Matrix)
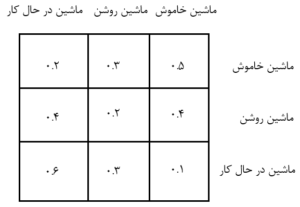
ماتریس انتقال یک جدول است که تمام احتمالات انتقال بین وضعیتها را نشان میدهد. برای مثال، فرض کنید وضعیتها در مثال ماشین بازی به صورت روبرو هستند:
این ماتریس نشان میدهد که اگر ماشین در حال کار باشد، احتمال اینکه در آینده روشن شود 30% و احتمال اینکه خاموش شود 10% است.
مقادیری که به عملها یا وضعیتها نسبت داده میشود و نشان میدهد که چقدر از انجام یک عمل در یک حالت راضی هستیم.
راهنمایی برای تصمیمگیری که در هر حالت چه عملی انجام شود.
تابعی که ارزش هر حالت را تعیین میکند و نشان میدهد که چه میزان پاداش میتوان از آن حالت کسب کرد.
8.تابع مدل (Model Function)
توصیف میکند که چگونه میتوان وضعیتهای بعدی را پیشبینی کرد و معمولاً شامل توزیعهای احتمال برای پاداشها و انتقالها است.
9.توزیع اولیه (Initial Distribution)
مشخص میکند از کدام حالت شروع میشود.به عنوان مثال، اگر ماشین به طور تصادفی روشن شود، احتمال اینکه ماشین در ابتدا خاموش باشد 50%، روشن 30% و در حال کار 20% است.
10.حالتهای نهایی (Terminal States)
حالتهایی که پس از ورود به آنها، فرایند پایان مییابد و دیگر نمیتوان به حالت دیگری رفت.
این اجزا به طور کلی به ما کمک میکنند تا فرایند مارکوف را مدلسازی و تحلیل کنیم.
مثال آب و هوا :
فرض کنیم که آب و هوای هر روز فقط به آب و هوای روز قبل بستگی دارد و تأثیری از روزهای قبلتر نمیگیرد.
در این مثال، دو حالت آب و هوا داریم: آفتابی و بارانی. انتقال بین این دو حالت با استفاده از احتمالها به صورت زیر تعریف شده است:
- اگر امروز آفتابی باشد:
- احتمال اینکه فردا هم آفتابی باشد 30% است.
- احتمال اینکه فردا بارانی باشد 70% است.
- اگر امروز بارانی باشد:
- احتمال اینکه فردا آفتابی باشد 50% است.
- احتمال اینکه فردا هم بارانی باشد 50% است.
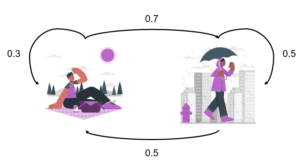
در این نمودار، فلشها نشاندهنده انتقال بین حالات مختلف آب و هوا و اعداد روی فلشها بیانگر احتمال وقوع هر انتقال هستند .
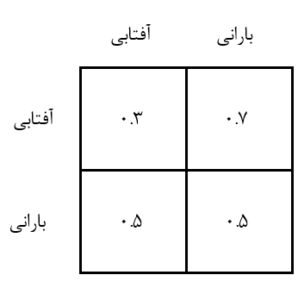
ماتریس انتقال
مجموع احتمالات در هر سطر باید برابر با 1 باشد، چرا که احتمال همه حالات ممکن است.
این مثال نشان میدهد که وضعیت آب و هوای فردا فقط به وضعیت امروز بستگی دارد و هیچ ارتباطی با وضعیت روزهای گذشته ندارد. این دقیقاً خاصیت مارکوف است، یعنی وضعیت آینده تنها به وضعیت فعلی وابسته است.
ترتیبی که هوشینو برای خواندن مطالب یادگیری تقویتی به شما پیشنهاد میکند:
4.زنجیره مارکوف بخش اول