Q-table چیست؟
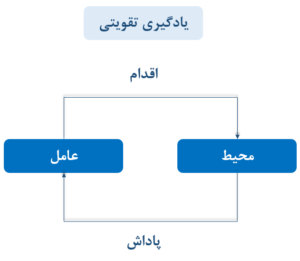
Q-table یک ساختار دادهای است که جوایز آینده مورد انتظار برای هر جفت اقدام-وضعیت را ذخیره میکند و بهعنوان مخزنی از پاداشهای مرتبط با اقدامات بهینه برای هر حالت در یک محیط خاص عمل میکند. این جدول بهعنوان راهنمایی برای عامل بهکار میرود و به او کمک میکند تا تعیین کند کدام اقدامات احتمالاً بهترین نتایج را به همراه خواهند داشت. با تعامل عامل با محیط، Q-table بهطور پویا بهروزرسانی میشود تا درک در حال تکامل عامل را منعکس کرده و تصمیمگیریهای آگاهانهتری را امکانپذیر سازد. جوهره Q-Learning در این جدول نهفته است، زیرا مقادیر Q ناشی از انجام اقدامهای مختلف در وضعیتهای مختلف را ذخیره کرده و به بهبود یادگیری عامل کمک میکند.
به عنوان مثال:
فرض کنید یک ربات در یک هزارتو قرار دارد و هدف آن رسیدن به یک نقطه خاص (خروجی) است. برای کمک به ربات در یادگیری بهترین راهها برای رسیدن به هدف، از جدول Q (Q-table) استفاده میکنیم.
وضعیتها و اقدامات
در این مثال، وضعیتهای مختلف میتوانند مکانهای مختلف ربات در هزارتو باشند، مانند S1 (شروع)، S2 (نزدیک دیوار)، S3 (نزدیکی خروجی)، S4(خروجی). همچنین، اقدامات ممکن برای ربات در هر وضعیت شامل A1 (حرکت به بالا)، A2(حرکت به پایین)، A3(حرکت به چپ)، A4(حرکت به راست).
Q-table
جدول Q بهصورت زیر خواهد بود:
| وضعیت | A1(بالا) | A2(پایین) | A3(چپ) | A4(راست) |
|---|---|---|---|---|
| S1 | 0.2 | 0.1 | 0.0 | 0.4 |
| S2 | 0.3 | 0.2 | 0.1 | 0.2 |
| S3 | 0.0 | 0.4 | 0.5 | 0.1 |
| S4 | 0.0 | 0.0 | 0.0 | 0.0 |
توضیحات جدول
- هر سلول در جدول Q نشاندهنده مقدار Q برای یک جفت خاص از وضعیت و اقدام است. برای مثال، در وضعیت S1، اگر ربات اقدام A4 (حرکت به راست) را انتخاب کند، انتظار دارد که مقدار پاداشی معادل4 دریافت کند.
- هر بار که ربات یک عمل را انجام میدهد و پاداشی را دریافت میکند، مقدار Q مربوط به آن وضعیت و عمل بهروزرسانی میشود. این به ربات کمک میکند تا با مرور زمان، یاد بگیرد که کدام اقدامات در هر وضعیت منجر به بیشترین پاداش میشوند.
با استفاده از جدول Q، ربات میتواند بهمرور زمان یاد بگیرد که در هر وضعیت بهترین اقدام کدام است تا به هدف (خروجی) برسد. بهعبارتی، Q-table به ربات کمک میکند تا تصمیمگیریهای بهینهتری داشته باشد و در نهایت به موفقیت برسد.
مراحل کلیدی الگوریتم Q-Learning
1.مقدمهسازی (Initialization): جدول Q با مقادیر دلخواه، معمولاً با صفرها، مقدمهسازی میشود.
2.کاوش و بهرهبرداری (Exploration and Exploitation): عامل با محیط تعامل میکند و اقدامهایی را بر اساس جدول Q انجام میدهد. این عامل تعادلی بین کاوش (تلاش برای انجام اقدامهای تصادفی به منظور جمعآوری اطلاعات) و بهرهبرداری (انتخاب اقدامهایی با بالاترین مقادیر Q به منظور حداکثر کردن جوایز) برقرار میکند.
3.انتخاب اقدام (Action Selection): عامل بر اساس مقادیر Q در وضعیت کنونی یک اقدام را انتخاب میکند. ممکن است اقدام با بالاترین مقدار Q را انتخاب کند (رویکرد طمعورزانه (greedy approach)) یا مقداری تصادفی برای کاوش اضافه کند (رویکرد ائپسیلون-طمعورزانه (epsilon-greedy approach)).
4.مشاهده و پاداش (Observation and Reward): عامل وضعیت بعدی را مشاهده کرده و بر اساس اقدام انجامشده، پاداشی دریافت میکند.
5.بهروزرسانی مقدار Q (Q-Value Update): مقدار Q برای جفت اقدام-وضعیت قبلی با استفاده از معادله بلمن بهروزرسانی میشود. این معادله پاداش فوری را با حداکثر پاداش آینده مورد انتظار تخفیفیافته از وضعیت بعدی ترکیب میکند.
6.تکرار (Iteration): مراحل ۲ تا ۵ تا زمانی که جدول Q همگرا شود، تکرار میشوند، به این معنی که مقادیر Q تثبیت میشوند و نشاندهنده این است که عامل سیاست بهینه را یاد گرفته است.
ملاحظات کلیدی
1.کاوش در برابر بهرهبرداری (Exploration vs. Exploitation): برقراری تعادل بین کاوش (تلاش برای چیزهای جدید) و بهرهبرداری (استفاده از آنچه که مؤثر است) برای یادگیری مؤثر بسیار مهم است.
2.عامل تخفیف (Discount Factor): این عامل اهمیت جوایز آینده را کنترل میکند. یک ضریب تخفیف بالاتر بر روی دستاوردهای بلندمدت تأکید میکند.
3.نرخ یادگیری (Learning Rate): این عامل میزان سرعت بهروزرسانی مقادیر Q را تعیین میکند. یک نرخ یادگیری بالاتر به یادگیری سریعتر ولی احتمالاً کمتر پایدار منجر میشود.
مزایای Q-Learning
1.نتایج بلندمدت، که دستیابی به آنها بسیار چالشبرانگیز است، به بهترین شکل ممکن با این استراتژی تحقق مییابند.
2.این الگوی یادگیری به طرز نزدیکی شبیه به نحوه یادگیری انسانها است؛ بنابراین، تقریباً ایدهآل به شمار میآید.
3.مدل میتواند اشتباهات انجامشده در حین آموزش را اصلاح کند.
4.پس از اینکه یک مدل اشتباهی را اصلاح کرد، احتمال تکرار آن اشتباه بهطور قابل توجهی کاهش مییابد.
5.این مدل قادر است یک راهحل ایدهآل برای یک مسئله خاص ارائه دهد.
معایب Q-Learning
1.معایب استفاده از نمونههای واقعی را باید در نظر گرفت. بهعنوان مثال، در زمینه یادگیری رباتها، سختافزار این رباتها معمولاً بسیار گران، مستعد خرابی و نیازمند نگهداری دقیق است. هزینه تعمیر یک سیستم رباتیکی نیز بالا است.
2.بهجای کنار گذاشتن کامل یادگیری تقویتی، میتوان آن را با سایر تکنیکها ترکیب کرد تا بسیاری از مشکلات آن کاهش یابد. یکی از ترکیبهای رایج، ادغام یادگیری عمیق با یادگیری تقویتی است.
محدودیتهای Q-Learning
1.فضاهای وضعیت و اقدام محدود(Finite State and Action Spaces):
Q-Learning نیاز به مجموعهای محدود و گسسته از وضعیتها و اقدامها دارد. این به این دلیل است که بر اساس نگهداری یک جدول (جدول Q) عمل میکند که در آن سطرها نمایانگر وضعیتها و ستونها نمایانگر اقدامها هستند. در محیطهایی که وضعیتها یا اقدامها بینهایت یا بسیار بزرگ هستند، جدول Q به طرز غیرقابل مدیریتی بزرگ میشود یا مدیریت آن غیرممکن میگردد.
2.مشکلات مقیاسپذیری (Scaling Issues):
با افزایش اندازه فضاهای وضعیت و اقدام، حافظه مورد نیاز برای ذخیره جدول Q و منابع محاسباتی لازم برای بهروزرسانی آن بهطور نمایی افزایش مییابد. این موضوع باعث میشود Q-Learning برای مسائل پیچیده مانند رباتیک در دنیای واقعی کمتر قابل اجرا باشد، جایی که فضای وضعیت میتواند شامل یک پیوستگی از مقادیر ممکن باشد.
3.سرعت همگرایی (Convergence Speed):
Q-Learning میتواند در همگرایی به سیاست بهینه بهخصوص در محیطهای بزرگ یا پیچیده کند باشد. این الگوریتم نیاز دارد تا تمام جفتهای وضعیت-اقدام را به اندازه کافی بازدید کند تا بتواند مقادیر Q را بهطور دقیق تخمین بزند، که این کار ممکن است زمان بسیار طولانی ببرد.
4.عدم تعمیم پذیری (Lack of Generalization):
از آنجایی که Q-Learning برای هر جفت وضعیت-اقدام خاص یک ارزش یاد میگیرد، نمیتواند در وضعیتهای مشابه تعمیم یابد. این در تضاد با روشهایی است که مقادیر Q را تقریب میزنند و میتوانند ارزش وضعیتهای نادیده را بر اساس شباهت به وضعیتهای قبلاً مشاهدهشده استنباط کنند.
5.نیاز به کاوش (Requirement for Exploration):
Q-Learning نیاز به برقراری تعادل دقیق بین کاوش اقدامهای جدید و بهرهبرداری از اقدامهای شناختهشده برای حداکثر کردن جوایز دارد. پیدا کردن استراتژی مناسب کاوش (مانند ε-greedy) حیاتی است و میتواند چالشبرانگیز باشد، بهویژه در محیطهایی که برخی از اقدامها میتوانند به عواقب منفی قابلتوجهی منجر شوند.
6.وابستگی به تمامی پاداشها (Dependency on All Rewards):
عملکرد Q-Learning به شدت به ساختار پاداشها وابسته است. اگر پاداشها نادر یا گمراهکننده باشند، این الگوریتم ممکن است نتواند سیاستهای مفیدی را یاد بگیرد.
7.مشاهده جزئی (Partial Observability):
Q-Learning فرض میکند که عامل دارای مشاهده کامل از وضعیت محیط است. در بسیاری از سناریوهای دنیای واقعی، عاملها فقط مشاهده جزئی دارند که میتواند منجر به یادگیری و تصمیمگیری غیر بهینه شود.
به دلیل این محدودیتها، پژوهشگران معمولاً به روشهای دیگری مانند شبکههای Q عمیق (DQN) روی میآورند که از شبکههای عصبی برای تقریب مقادیر Q استفاده میکنند و میتوانند با فضاهای وضعیت پیوسته و بزرگ مقابله کنند، یا انواع دیگری از الگوریتمهای یادگیری که قادر به مدیریت مشاهده جزئی و پاداشهای نادر هستند.
کاربردهای Q-Learning
کاربردهای Q-Learning، یک الگوریتم یادگیری تقویتی، در زمینههای مختلفی وجود دارد. در اینجا چند مورد قابل توجه آورده شده است:
1.بازیهای آتاری (Atari Games): بازیهای کلاسیک آتاری ۲۶۰۰ اکنون با استفاده از Q-learning قابل بازی هستند. در بازیهایی مانند Space Invaders و Breakout، شبکههای عمیق Q (DQN)، که نسخهای از Q-learning است و از شبکههای عصبی عمیق استفاده میکند، عملکردی فراتر از انسان را نشان داده است.
2.کنترل ربات (Robot Control): Q-learning در رباتیک برای انجام وظایفی مانند ناوبری و کنترل رباتها استفاده میشود. با استفاده از الگوریتمهای Q-learning، رباتها میتوانند یاد بگیرند که چگونه در محیطها حرکت کنند، از موانع دوری کنند و حرکات خود را بهینهسازی کنند.
3.مدیریت ترافیک (Traffic Management): سیستمهای مدیریت ترافیک خودروهای خودران از Q-learning استفاده میکنند. این سیستم با بهینهسازی برنامهریزی مسیر و زمانبندی چراغهای ترافیکی، موجب کاهش ترافیک و بهبود جریان کلی ترافیک میشود.
4.معاملهگری الگوریتمی (Algorithmic Trading): استفاده از Q-learning برای اتخاذ تصمیمات معاملاتی در زمینه معاملهگری الگوریتمی مورد بررسی قرار گرفته است. این روش به عوامل خودکار این امکان را میدهد که بهترین استراتژیها را از دادههای گذشته بازار یاد بگیرند و به شرایط متغیر بازار سازگار شوند.
5.برنامههای درمانی شخصیسازیشده (Personalized Treatment Plans): در حوزه پزشکی، از Q-learning برای ایجاد برنامههای درمانی منحصر به فرد استفاده میشود. با استفاده از دادههای بیماران، عوامل میتوانند مداخلات شخصیسازیشدهای را پیشنهاد دهند که پاسخهای فردی به درمانهای مختلف را در نظر بگیرند.

ترتیبی که هوشینو برای خواندن مطالب یادگیری تقویتی به شما پیشنهاد میکند:
9.الگوریتم Q-Learning بخش دوم