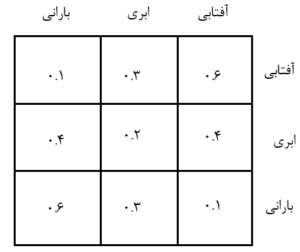
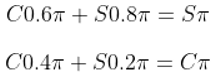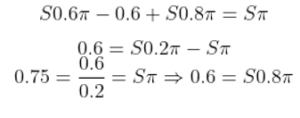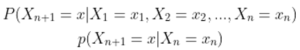تفاوت بین Q-Learning و SARSAمروری بر Q-Learning
Q-learning یک الگوریتم یادگیری تقویتی خارج از سیاست (off-policy) است که ارزش بهترین عمل ممکن را مستقل از سیاستی که دنبال میشود، یاد میگیرد.
هدف این الگوریتم یادگیری تابع ارزش عمل بهینه Q∗(s,a) است که بیشترین پاداش مورد انتظار آینده را برای انجام عمل a در حالت s میدهد. قانون بهروزرسانی برای Q-learning به این صورت است:
![]()
مروری بر SARSA
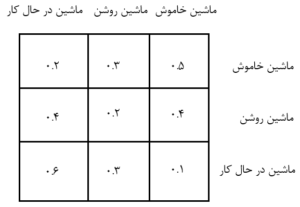
در مقابل، SARSA یک الگوریتم یادگیری تقویتی روی سیاست (on-policy) است. این الگوریتم نیز یک تابع ارزش عمل را یاد میگیرد، اما تخمینهای خود را براساس عملی که واقعاً توسط سیاست فعلی انجام شده، بهروزرسانی میکند. قانون بهروزرسانی برای SARSA به این صورت است:
![]()
در SARSA، مقدار Q(s,a) با توجه به عمل واقعی a′ که در حالت بعدی s′ انتخاب شده است، بهروزرسانی میشود. این تفاوت کلیدی بین SARSA و Q-learning است، زیرا SARSA وابسته به سیاست جاری است.
تفاوتهای کلیدی بین Q-Learning و SARSA
1.اکتشاف در مقابل بهرهبرداری (Exploration vs. Exploitation)
- Q-Learning: بهعنوان یک روش خارج از سیاست (off-policy) است، Q-learning مقدارهای Q خود را با استفاده از بیشترین پاداش ممکن آینده بهروزرسانی میکند، بدون توجه به اینکه کدام عمل انجام شده است. این ویژگی میتواند به جستجوی تهاجمیتر محیط منجر شود.
در واقع، Q-learning همواره به دنبال بیشترین پاداش مورد انتظار در حالتهای بعدی است، حتی اگر این پاداش مربوط به عملی نباشد که سیاست فعلی انتخاب کرده است. به همین دلیل، Q-learning نسبت به SARSA تمایل بیشتری به کشف و آزمایش گزینههای جدید دارد.
- SARSA: بهعنوان یک روش روی سیاست (on-policy) است، SARSA مقدارهای Q خود را براساس اعمالی که واقعاً توسط سیاست انجام شدهاند، بهروزرسانی میکند. این ویژگی معمولاً به یک رویکرد محتاطانهتر منجر میشود که به شکل محافظهکارانهتری بین اکتشاف (exploration) و بهرهبرداری (exploitation) تعادل برقرار میکند.
به بیان دیگر، چون SARSA براساس اعمال واقعی و پاداشهای دریافتی در مسیر سیاست فعلی خود عمل میکند، کمتر از Q-learning تمایل به انجام حرکات ریسکی و جستجوهای تهاجمی دارد و با احتیاط بیشتری به محیط پاسخ میدهد.
2.بهروزرسانی قوانین (Update Rules)
- Q-Learning: از عملگر بیشینه (max) برای بهروزرسانی مقادیر Q استفاده میکند و روی بهترین عمل ممکن تمرکز دارد.
این به این معناست که در هر مرحله، Q-learning همواره مقداری را انتخاب میکند که بیشترین پاداش مورد انتظار را به همراه دارد، بدون توجه به اینکه سیاست فعلی چه عملی را انتخاب کرده است. این ویژگی باعث میشود Q-learning به دنبال بهینهترین تصمیمها باشد، حتی اگر این تصمیمها با عمل واقعی گرفتهشده توسط سیاست جاری متفاوت باشند.
- SARSA: از عملی که توسط سیاست فعلی انتخاب شده است استفاده میکند، که باعث میشود فرآیند یادگیری بیشتر به رفتار سیاست وابسته باشد.
این بدان معناست که SARSA مقادیر Q را براساس عمل واقعی انجامشده طبق سیاست فعلی بهروزرسانی میکند، و به همین دلیل، یادگیری آن به شدت به نحوه رفتار سیاست در محیط بستگی دارد. این وابستگی به سیاست باعث میشود SARSA بهطور طبیعی تعادلی میان اکتشاف و بهرهبرداری برقرار کند، و در نتیجه رفتار محتاطانهتری را نسبت به Q-learning ارائه دهد.
3.یادگیری Off-Policy در مقابل On-Policy (On-policy vs. Off-policy Learning)
- Q-Leaning: یک روش خارج از سیاست (off-policy) است، به این معنا که ارزش سیاست بهینه را بهطور مستقل از اعمالی که عامل انجام میدهد، یاد میگیرد.
این یعنی Q-learning بدون توجه به اینکه عامل چه عملی را در هر حالت انتخاب میکند، همواره در پی یادگیری بهترین سیاست ممکن است. به دلیل این استقلال از سیاست فعلی عامل، Q-learning میتواند بدون تبعیت از سیاست جاری به بیشترین پاداشهای ممکن دست یابد و ارزشهای Q را بر اساس پاداشهای بهینهسازیشده بهروزرسانی کند.
- SARSA: یک روش روی سیاست (on-policy) است، به این معنا که ارزش سیاستی را که عامل در حال دنبال کردن آن است، یاد میگیرد.
این یعنی SARSA بهطور مستقیم با استفاده از سیاست فعلی عامل، مقدارهای Q را بهروزرسانی میکند. در نتیجه، یادگیری SARSA به اعمالی که عامل طبق سیاست جاری خود انجام میدهد، وابسته است. این ویژگی باعث میشود SARSA ارزشهای Q را براساس سیاست جاری به دست آورد و بهطور طبیعی میان اکتشاف و بهرهبرداری تعادلی ایجاد کند.
به طور خلاصه، Q-Learning بیشتر به کاوش تمایل دارد، در حالی که SARSA تلاش میکند یک تعادل بین کاوش و بهرهبرداری برقرار کند. این تفاوتها تأثیر زیادی بر روی نحوه یادگیری و بهینهسازی در محیطهای مختلف دارند.
| ویژگی | Q-Leaning | SARSA |
|---|---|---|
| نوع سیاست (Policy Type) | خارج از سیاست ( Off-policy) | روی سیاست ( On-policy) |
| بهروزرسانی قوانین (Update Rule) | ||
| رویکرد یادگیری ( Learning Approach) | ارزش سیاست بهینه را یاد میگیرد. | ارزش سیاست فعلی را یاد میگیرد. |
| ثبات ( Stability) | بهخاطر بهروزرسانیهای خارج از سیاست، ممکن است کمتر پایدار باشد. | بهخاطر بهروزرسانیهای درونسیاست، پایدارتر است. |
| سرعت همگرایی ( Convergence Speed) | معمولاً همگرایی سریعتری به سیاست بهینه دارد. | معمولاً همگرایی کندتری به سیاست بهینه دارد. |
| تاثیر اکتشاف ( Exploration Impact) | سیاست کاوش میتواند با سیاست یادگیری متفاوت باشد. | کاوش بهطور مستقیم بر بهروزرسانیهای یادگیری تأثیر میگذارد. |
| انتخاب اقدام برای بروزرسانی ( Action Selection for Update) | بهروزرسانیها بر اساس حداکثر پاداش آینده انجام میشوند. | بهروزرسانیها بر اساس عملی که واقعاً انجام شدهاند، صورت میگیرند. |
| کاربرد (Use Case Suitability) | مناسب برای محیطهایی که کارایی حیاتی است. | مناسب برای محیطهایی که ثبات حیاتی است. |
| سناریوهای نمونه ( Example Scenarios) | بازیسازی (Gaming)، رباتیک (robotics)، تجارت مالی (financial trading) | بهداشت و درمان (Healthcare)، مدیریت ترافیک تطبیقی (adaptive traffic management)، یادگیری شخصیسازیشده (personalized learning) |
| رسیدگی به اقدامات اکتشافی ( Handling of Exploratory Actions) | بیشتر کارآمد است اما ممکن است با تجربیات واقعی کمتر همراستا باشد. | بیشتر محتاط و همراستا با تجربیات واقعی است. |
| تمرکز الگوریتم ( Algorithm Focus) | بر روی یافتن بهترین اقدامات ممکن تمرکز دارد. | بر روی اقداماتی که در حال حاضر توسط عامل انجام میشود تمرکز دارد. |
| تحمل ریسک ( Risk Tolerance) | تحمل بالاتری برای ریسک و بیثباتی دارد. | تحمل کمتری برای ریسک دارد و ایمنی را در اولویت قرار میدهد. |
1.Q-Learning: کارایی حیاتی
Q-Learning یک الگوریتم یادگیری تقویتی غیرنظارتی است که هدف آن یادگیری یک سیاست بهینه برای انتخاب عملها در یک محیط است. در Q-Learning، عامل (Agent) به دنبال یادگیری بهترین عمل برای هر حالت است تا حداکثر پاداش را کسب کند.
کارایی حیاتی: در محیطهایی که کارایی (Performance) بالایی نیاز است، Q-Learning میتواند انتخابهای بهتری را انجام دهد زیرا از تجربیات گذشتهاش برای بهبود تصمیمات آینده استفاده میکند. به عبارت دیگر، Q-Learning به عامل این امکان را میدهد که خود را سریعاً با تغییرات محیط سازگار کند و یادگیری سریعی داشته باشد.
مثال: فرض کنید که شما یک ربات در یک محیط پیچیده دارید که باید از میان موانع عبور کند. در اینجا، کارایی به معنای توانایی ربات برای حرکت سریع و بدون برخورد با موانع است. با استفاده از Q-Learning، ربات میتواند تجربیات خود را ذخیره کند و بهترین راه را برای عبور از موانع یاد بگیرد. اگر ربات به یک مانع برخورد کند، آن تجربه را ذخیره کرده و در دفعات بعدی از آن پرهیز میکند، بنابراین کارایی آن افزایش مییابد.
2.SARSA: ثبات حیاتی
SARSA (State-Action-Reward-State-Action) نیز یک الگوریتم یادگیری تقویتی است، اما تفاوت آن با Q-Learning در این است که SARSA از سیاست فعلی خود برای بهروزرسانی Q-Values استفاده میکند. این به این معنی است که SARSA یاد میگیرد که چطور بهطور پیوسته با سیاست فعلیاش عمل کند.
ثبات حیاتی: در محیطهایی که ثبات (Stability) مهم است، SARSA میتواند مفیدتر باشد. زیرا این الگوریتم در هنگام یادگیری به عملهایی که بر اساس سیاست فعلی انتخاب میشوند، بیشتر توجه میکند و به همین دلیل، تغییرات شدید در یادگیری را کاهش میدهد. این باعث میشود که رفتار عامل در مواجهه با تغییرات ناگهانی محیط کمتر تحت تأثیر قرار گیرد و ثبات بیشتری داشته باشد.
مثال: فرض کنید که در یک بازی ویدیویی، شخصیت شما باید در مقابل دشمنان متفاوت عمل کند. در اینجا، ثبات به معنای توانایی شخصیت برای حفظ یک استراتژی مشخص و قابل پیشبینی است. با استفاده از SARSA، شخصیت بازی به تدریج میآموزد که در شرایط خاص چگونه عمل کند و با استفاده از اطلاعات گذشته، رفتار خود را به تدریج بهبود میبخشد. این الگوریتم از انتخابهای فعلی خود استفاده میکند و این باعث میشود که تغییرات ناگهانی در رفتار شخصیت کمتر باشد.
بطور کلی Q-Learning برای محیطهایی که کارایی حیاتی است مناسب است زیرا به سرعت میتواند بهترین عملها را یاد بگیرد و بهینهسازی کند و SARSA برای محیطهایی که ثبات حیاتی است مناسب است زیرا از سیاست فعلی خود پیروی میکند و یادگیری تدریجیتری دارد که تغییرات را به حداقل میرساند.
نقاط قوت و ضعف (Strengths and Weaknesses)
Q-Learning
نقاط قوت (Strengths):
- معمولاً سریعتر به سیاست بهینه همگرا میشود.
این سرعت همگرایی بیشتر به این دلیل است که Q-learning از عملگر بیشینه (max) استفاده میکند و همیشه به دنبال بهترین پاداشهای ممکن در آینده است، حتی اگر سیاست فعلی این گزینهها را انتخاب نکرده باشد. این ویژگی به آن کمک میکند تا بهطور مؤثرتری از تجربیات قبلی استفاده کند و به سرعت به یک سیاست بهینه نزدیک شود.
- Q-learning در اکتشاف محیط بسیار تهاجمیتر است که میتواند در سناریوهای پیچیده مفید باشد.
این رویکرد تهاجمی به این معناست که Q-learning تمایل دارد گزینههای بیشتری را آزمایش کند و به دنبال بیشترین پاداشها باشد، حتی اگر این گزینهها ریسک بیشتری داشته باشند. در محیطهای پیچیده، جستجوی تهاجمی میتواند به شناسایی سریعتر بهترین استراتژیها و بهینهسازی عملکرد کمک کند، زیرا عامل قادر است از تجربیات متنوع بیشتری برای یادگیری استفاده کند.
نقاط ضعف (Weaknesses):
- Q-learning میتواند به دلیل اکتشاف تهاجمی، از نظر پایداری کمتر قابل اعتماد باشد.
این اکتشاف تهاجمی میتواند منجر به نوسانات بیشتری در مقادیر Q شود، زیرا عامل ممکن است به طور مکرر به حالتهای جدید و ناشناخته وارد شود و از تصمیمات غیر بهینه تبعیت کند. این رفتار میتواند باعث شود که یادگیری در مراحل اولیه ناپایدار باشد و ممکن است زمان بیشتری طول بکشد تا به همگرایی برسد و عملکرد بهینهای را پیدا کند.
- Q-learning ممکن است به سیاستهای زیر بهینه همگرا شود اگر اکتشاف به درستی مدیریت نشود.
این بدان معناست که اگر عامل به اندازه کافی به اکتشاف محیط نپردازد یا بیش از حد بر بهرهبرداری از اطلاعات موجود تمرکز کند، ممکن است به نتایج نامطلوبی دست یابد و از پیدا کردن بهترین سیاست باز بماند. بنابراین، مدیریت مناسب اکتشاف، مانند استفاده از استراتژیهای اکتشافی مناسب، برای اطمینان از این که عامل بهطور مؤثری همه گزینههای ممکن را بررسی میکند، بسیار مهم است.
SARSA
نقاط قوت (Strengths):
- فرآیند یادگیری در SARSA به دلیل رویکرد روی سیاست (on-policy) پایدارتر است.
این ثبات به این دلیل است که SARSA مقادیر Q را براساس اعمال واقعی انجامشده طبق سیاست فعلی بهروزرسانی میکند. به همین دلیل، یادگیری کمتر تحت تأثیر نوسانات ناشی از اکتشافات تهاجمی قرار میگیرد و معمولاً به تغییرات تدریجیتری در مقدارهای Q منجر میشود. این ویژگی به عامل کمک میکند تا به آرامی به یک سیاست بهینه نزدیک شود و در عین حال رفتار مطمئنتری را در محیط ارائه دهد.
- SARSA در مدیریت محیطهایی با سطوح بالای عدم قطعیت بهتر عمل میکند.
این به این دلیل است که SARSA بهطور مستقیم به سیاست فعلی وابسته است و مقادیر Q را براساس اعمال واقعی انجامشده بهروزرسانی میکند. این رویکرد به آن اجازه میدهد تا بهتدریج و با دقت بیشتری یاد بگیرد و به نوسانات غیرمنتظره در پاداشها و وضعیتها پاسخ دهد. در محیطهای نامشخص، این ویژگی به SARSA کمک میکند تا بهطور مؤثری به تغییرات پاسخ دهد و به سیاستهای بهینهای دست یابد که متناسب با شرایط پیچیده و متغیر محیط باشد.
نقاط ضعف (Weaknesses):
- SARSA ممکن است به دلیل تعادل بین اکتشاف و بهرهبرداری، به آهستگی همگرا شود.
این تعادل به این معناست که SARSA همواره تلاش میکند تا بین آزمایش گزینههای جدید (اکتشاف) و استفاده از اطلاعات موجود برای بهینهسازی پاداشها (بهرهبرداری) تعادل برقرار کند. این رویکرد محتاطانه میتواند به فرآیند یادگیری زمان بیشتری نیاز داشته باشد تا به یک سیاست بهینه نزدیک شود، زیرا عامل ممکن است زمان بیشتری را صرف آزمایش رفتارهای مختلف کند و به همین دلیل، سرعت همگرایی آن کمتر از الگوریتمهای تهاجمیتر مانند Q-learning باشد.
- SARSA ممکن است به اندازه Q-learning بهطور کامل اکتشاف نکند و در نتیجه ممکن است سیاستهای بهینه را از دست بدهد.
این به این دلیل است که SARSA به طور مستقیم به رفتار سیاست فعلی وابسته است و بر اساس اعمال واقعی انجامشده، مقادیر Q را بهروزرسانی میکند. این وابستگی میتواند به این معنا باشد که SARSA کمتر به سمت گزینههای جدید و ناشناخته میرود و ممکن است به نتایج زیر بهینه دست یابد. بنابراین، در برخی از سناریوها، SARSA ممکن است فرصتهای بالقوهای را برای بهبود عملکرد خود از دست بدهد.
نتیجه گیری
در نتیجه، Q-learning و SARSA الگوریتمهای بنیادی یادگیری تقویتی هستند که رویکردهای متفاوتی دارند: Q-learning یک روش خارج از سیاست (off-policy) است، زیرا به دنبال یافتن مقادیر بهینه برای جدول Q است که در آینده بیشترین بازده را به همراه داشته باشد. این ویژگی آن را برای محیطهای پویا مانند بازیها و رباتیک مناسب میسازد. از سوی دیگر، SARSA یک روش روی سیاست (on-policy) است، زیرا از عمل فعلی عامل یاد میگیرد و به همین دلیل از نظر ایمنی و ثبات بیشتر، بهویژه در حوزههای مراقبتهای بهداشتی، کنترل ترافیک و مدیریت، بهتر عمل میکند.
مفید است که هر کسی که میخواهد الگوریتم مناسب را انتخاب کند، با تفاوتهای موجود در استراتژیهای یادگیری، قوانین بهروزرسانی و کاربرد هر الگوریتم آشنا باشد. بنابراین، نیاز به تعادل بین همگرایی سریع و اکتشاف ایمن در محیطها وجود دارد.
سوالات متدوال
تفاوت اصلی در قانون بهروزرسانی بین Q-learning و SARSA چیست؟
بهروزرسانی مقدار Q در Q-learning بر اساس حداکثر پاداش ممکن در حالت بعدی انجام میشود، نه بر اساس پاداشی که در عمل انتخاب شده است (روش خارج از سیاست یا off-policy) این ویژگی اهمیت دارد زیرا SARSA مقدار Q را با استفاده از عملی که واقعاً توسط عامل انجام شده است، بهروزرسانی میکند (روش روی سیاست یا on-policy)
این تفاوت بنیادی باعث میشود که Q-learning بتواند بهطور تهاجمیتری به دنبال بهترین سیاستها باشد، در حالی که SARSA از رویکردی محتاطانهتر استفاده میکند که به اعمال واقعی و پاداشهای دریافتی وابسته است.
تفاوت از نظر یادگیری سیاست در Q-learning و SARSA.
Q-learning ارزش سیاست بهینه را یاد میگیرد و به اعمال عامل وابسته نیست. در مقابل، SARSA به یادگیری ارزش سیاستی که عامل در یک لحظه خاص دنبال میکند، متمرکز است.
این به این معناست که Q-learning میتواند بدون توجه به تصمیمات فعلی عامل، به دنبال بهترین نتایج ممکن باشد، در حالی که SARSA به طور مستقیم تحت تأثیر اعمال و پاداشهایی است که عامل در حین یادگیری دریافت میکند. این تفاوت در رویکرد یادگیری میتواند بر نحوه عملکرد و سرعت همگرایی هر الگوریتم تأثیر بگذارد.
در Q-learning، (off-policy) به موقعیتهایی اشاره دارد که یک عامل عملی را انتخاب میکند که توسط الگوریتم مشاهده نشده است.
روش خارج از سیاست (off-policy) به این معناست که مقدار Q به ارزش بهترین عمل ممکن در حالت بعدی بهروزرسانی میشود، در حالی که به اعمالی که احتمالاً عامل انتخاب میکند، توجهی نمیشود.
این رویکرد به Q-learning اجازه میدهد تا از اطلاعات حداکثری برای یادگیری استفاده کند، حتی اگر عامل در حال حاضر اقداماتی غیر از بهترین عمل ممکن را انجام دهد. این ویژگی به Q-learning کمک میکند تا به سرعت به سیاستهای بهینه نزدیک شود و از تجربیات متنوع برای بهبود یادگیری استفاده کند.
کدام الگوریتم به سرعت به سیاست بهینه همگرا میشود؟
الگوریتم Q-learning به طور کلی به سیاست بهینه نزدیکتر همگرا میشود، زیرا تمایل دارد از عملگر بیشینه (max) برای پاداشهای آینده مورد انتظار استفاده کند. با این حال، این ویژگی ممکن است بر پایداری الگوریتم تأثیر بگذارد.
به این معنا که اگرچه Q-learning میتواند سریعتر به یک سیاست بهینه دست یابد، اما این فرآیند ممکن است با نوسانات و عدم ثبات همراه باشد. این ناپایداری میتواند در مراحل اولیه یادگیری و در نتیجه اکتشافات تهاجمی بیشتر ایجاد شود. بنابراین، در حالی که Q-learning سریعتر همگرا میشود، لازم است که مراقبتهای لازم برای حفظ پایداری نیز لحاظ شود.
ترتیبی که هوشینو برای خواندن مطالب یادگیری تقویتی به شما پیشنهاد میکند:
10.الگوریتم Q-Learning بخش سوم
13. تفاوت بین Q-Learning و SARSA