

یادگیری تقویتی چیست ؟
به یادگیری نحوه تعامل یک وضعیت به یک اقدام به طوری که یک سیگنال پاداش عددی را به حداکثر نماید ، یادگیری تقویتی میگویند .
یادگیری تقویتی نوعی یادگیری ماشین است که در آن یک مدل یاد میگیرد چگونه در یک محیط خاص عمل کند. این مدل تصمیمهایی میگیرد و نتایج هر تصمیم را دریافت میکند. اگر تصمیم درست باشد، پاداش مثبت و اگر اشتباه باشد، پاداش منفی دریافت میکند. بر خلاف یادگیری بانظارت (Supervised Learning) این مدلها به طور مستقل یاد میگیرند و نیازی به برچسبگذاری ندارند .
یادگیری تقویتی در موقعیتهایی که باید تصمیمات متوالی گرفته و یا هدفهای بلندمدت داشته باشد، بسیار خوب عمل میکند. مثالهایی از این کاربردها شامل بازی شطرنج و رباتیک است.
هدف اصلی در یادگیری تقویتی، حداکثر کردن دقت و کارایی است تا بیشترین پاداشهای مثبت را مدل دریافت نماید.
این روش مشابه فرآیند یادگیری آزمایش و خطا است که انسانها برای رسیدن به اهداف خود استفاده میکنند . اقداماتی که به سمت هدف شما پیش میروند تقویت میشوند، در حالی که اقداماتی که از هدف منحرف میشوند نادیده گرفته میشوند.
دلایل اصلی استفاده از یادگیری تقویتی عبارتند از:
1. یادگیری از تعاملات
الگوریتم یادگیریتقویتی یک الگوریتم تعاملی است .
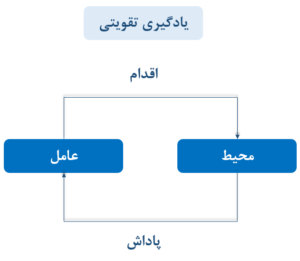
تعامل در یادگیری تقویتی به معنای ارتباط بین عامل (Agent) و محیط (Environment) است.
تعامل در یادگیری تقویتی به عامل کمک میکند تا از تجربیاتش یاد بگیرد و به تدریج بهترین راهها را برای رسیدن به هدفش پیدا کند.این فرآیند به شدت شبیه به یادگیری انسانی است، جایی که ما از تجربههای خود یاد میگیریم و برای بهبود تلاش میکنیم.
2. تصمیمگیری قابل تنظیم
تصمیمگیری در یادگیری تقویتی به این معناست که عامل میتواند بر اساس تغییرات محیط خود عمل کند.
مثلاً فرض کنید یک ربات در یک اتاق پر از مانع است. اگر یکی از موانع جابهجا شود، ربات باید بتواند تصمیم بگیرد که چگونه به سمت هدفش برود. این یعنی ربات باید به سرعت به شرایط جدید پاسخ دهد و تصمیمات خود را بر اساس آن تغییر دهد.
به عبارت سادهتر، عامل نمیتواند فقط یک بار یاد بگیرد و تمام؛ بلکه باید همیشه آماده باشد تا با تغییرات محیطی سازگار شود و بهترین تصمیم را بگیرد.
3. یادگیری مداوم
به این معنی است که عامل همیشه در حال یادگیری میباشد و از بازخوردهایی که دریافت میکند، برای تصمیمات خود استفاده میکند.
این بازخوردها ممکن است دیر به او برسند یا خیلی کم باشند.
برای مثال، اگر ربات یک اقدام اشتباه انجام دهد و بعداً متوجه شود که آن اقدام باعث تنبیه شده است، این بازخورد ممکن است کمی زمان ببرد تا به او برسد. اما ربات یاد میگیرد که در آینده آن کار را انجام ندهد.
بنابراین، حتی اگر بازخوردها کم و دیر دریافت شود ، ربات به تدریج بهبود مییابد و تصمیمات بهتری خواهد گرفت .
دو مشخصه مهم در یادگیری تقویتی
دو مشخصه جستجو با آزمون و خطا و پاداشهای تاخیردار دو ویژگی بسیار مهم در یادگیریتقویتی هستند .
به عنوان مثال، فرض کنید یک ربات در حال یادگیری نحوه حرکت در یک اتاق است. وقتی ربات به هدفش (مثلاً رسیدن به یک توپ) نزدیک میشود، یک پاداش (مثل یک علامت مثبت یا یک امتیاز) دریافت میکند. اما اگر به دیوار برخورد کند، تنبیه (مثل یک علامت منفی) خواهد شد .
ربات از هر اقدام خود یاد میگیرد. اگر ببیند که مسیر خاصی به پاداش منجر میشود، دفعه بعد آن مسیر را بیشتر انتخاب میکند. همچنین، این الگوریتمها میتوانند برای پاداشها صبر کنند؛ مثلاً ممکن است ربات مجبور شود چندین اقدام انجام دهد تا در نهایت به هدف برسد و پاداش را دریافت کند، اما آن را به خاطر میسپارد تا در آینده تصمیمات بهتری بگیرد. در نتیجه، به تدریج ربات بهترین مسیرها را برای رسیدن به اهداف یاد میگیرد.
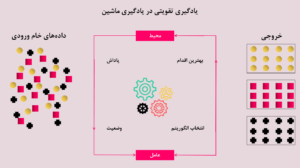
اجزای کلیدی یک سیستم یادگیری تقویتی عبارتند از :
1.عامل (Agent) : موجودیتی که محیط خود را درک کرده ، تصمیم گیری میکند و با آن تعامل دارد .
2.محیط (Environment) :
تعاریف مختلف
هر چیزی که عامل برای رسیدن به هدف خود با آن تعامل میکند .
محیط فضایی است که عامل در آن فعالیت میکند و شامل تمام عواملی است که بر روی تصمیمات و عملکرد عامل تأثیر میگذارد. این محیط میتواند شامل سایر عوامل، شرایط و وضعیتها باشد و عامل با انجام اقداماتی در آن، بازخوردهایی مانند پاداش یا جریمه دریافت میکند تا یاد بگیرد چگونه بهتر عمل کند .
3.وضعیت (State) :
تعاریف مختلف
وضعیت فعلی محیط که توسط عامل درک میشود .
وضعیت در یادگیری تقویتی به معنای نمایی از شرایط کنونی محیط است که عامل بر اساس آن تصمیمگیری میکند. این وضعیت شامل اطلاعاتی است که به عامل کمک میکند تا بفهمد چه اقدامی باید انجام دهد. به عبارت دیگر، وضعیت نشاندهنده ویژگیها و شرایط محیط در لحظهای خاص است و عامل با استفاده از آن، بهترین تصمیم را برای رسیدن به هدفش اتخاذ میکند.
4.اقدام (Action) :
تعاریف مختلف
تصمیمات یا حرکت هایی که عامل می تواند بگیرد .
هر تصمیمی که یک عامل درمورد نحوه تعامل با محیط خود میگیرد .
اقدام در یادگیری تقویتی به معنای عملی است که عامل در یک وضعیت خاص انجام میدهد تا بر روی محیط تأثیر بگذارد. این اقدام میتواند شامل انتخاب یک عمل خاص، تغییر وضعیت محیط یا برقراری تعامل با دیگر عوامل باشد. هدف از انجام اقدام، به حداکثر رساندن پاداش دریافتی یا بهبود عملکرد در آینده است. به عبارت دیگر، اقدامها راههایی هستند که عامل میتواند از آنها برای دستیابی به هدفهایش استفاده کند و بر اساس بازخوردی که از محیط دریافت میکند، تصمیم میگیرد که در وضعیتهای آینده چه اقداماتی را انجام دهد.
5.پاداش (Reward) :
تعاریف مختلف
بازخورد محیط در پاسخ به اقدام عامل ، نشان دهنده موفقیت یا شکست عمل است.
بازخوردی که پس از هر اقدام از محیط به عامل باز می گردد. این به عامل کمک می کند تا خود را ارزیابی کند.
پاداش در یادگیری تقویتی به معنای بازخوردی است که عامل پس از انجام یک اقدام در یک وضعیت خاص از محیط دریافت میکند. این بازخورد میتواند مثبت (پاداش) یا منفی (جریمه) باشد و به عامل کمک میکند تا بفهمد چقدر اقدامش موفقیتآمیز بوده است. هدف از پاداش، هدایت یادگیری عامل است؛ یعنی هرچه پاداش بیشتر باشد، احتمال تکرار آن اقدام در آینده افزایش مییابد. به عبارت دیگر، پاداشها ابزاری هستند که عامل را به سمت یادگیری و بهبود استراتژیهای تصمیمگیری سوق میدهند.
6.سیاست (Policy) :
تعاریف مختلف
استراتژی که عامل برای تعیین اقدامات خود بر اساس وضعیت فعلی استفاده می کند.
تکنیکی که یک عامل برای تصمیم گیری در مورد اقدام بعدی استفاده می کند.
سیاست در یادگیری تقویتی به معنای یک استراتژی است که عامل برای انتخاب اقداماتش در پاسخ به وضعیتهای مختلف استفاده میکند. این سیاست میتواند به صورت یک تابع باشد که برای هر وضعیت، اقدام مناسب را تعیین میکند.
هدف سیاست این است که به عامل کمک کند تا با توجه به وضعیتهای مختلف، بهترین اقدام را انتخاب کند تا در نهایت پاداشهای بیشتری را کسب کند و به هدفهایش برسد. به طور کلی، سیاست نقش کلیدی در یادگیری و تصمیمگیری مؤثر عامل دارد.
7.تابع ارزش (Value Function):
تعاریف مختلف
یک تابع که پاداشهای آینده مورد انتظار را که میتوان از هر وضعیت به دست آورد، تخمین میزند.
تابع ارزش در یادگیری تقویتی به معنای یک تابع ریاضی است که برای هر وضعیت، مقدار ارزش آن وضعیت را تخمین میزند. این ارزش نشاندهنده پیشبینی مجموع پاداشهایی است که عامل میتواند در آینده از آن وضعیت خاص به دست آورد، با توجه به سیاستی که در حال حاضر دنبال میکند.
هدف تابع ارزش این است که به عامل کمک کند تا تصمیمات بهتری بگیرد و اقداماتی را انتخاب کند که منجر به بیشترین پاداش ممکن شود. به عبارت دیگر، تابع ارزش ابزاری است که به عامل کمک میکند تا ارزش وضعیتها و اقداماتی که میتواند انجام دهد را درک کند.
8.تابع Q (Q-Value(Action-Value)Function) :
تابعی که پاداش های مورد انتظار آینده را برای انجام یک اقدام خاص در یک وضعیت مشخص تخمین می زند.
مثال عملیاتی از موارد بالا
بازی مار و پله ، در این بازی، هدف بازیکن این است که با انجام حرکات مناسب از خانهی شروع (خانهی ۱) به خانهی پایان (خانهی ۱۰۰) برسد. بازیکن باید تلاش کند از مارها دوری کرده و با استفاده از نردبانها سریعتر به هدف برسد.
1.عامل (Agent)
عامل همان بازیکن است که در این بازی قصد دارد به خانهی ۱۰۰ برسد. عامل تصمیم میگیرد چه اقدامی انجام دهد (برای مثال، حرکت به جلو در خانهها).
2.محیط (Environment)
محیط، همان صفحهی بازی مار و پله است که شامل خانهها، مارها و نردبانها میباشد. عامل با این محیط تعامل دارد و اقداماتش را بر اساس وضعیت فعلی محیط انجام میدهد.
3.وضعیت (State)
هر خانهای که بازیکن در آن قرار دارد، یک وضعیت محسوب میشود. به عنوان مثال، اگر بازیکن در خانهی ۲۵ باشد، وضعیت فعلی او (خانهی ۲۵) است. وضعیتها میتوانند اطلاعات بیشتری را نیز شامل شوند؛ مثلاً اینکه آیا بازیکن در نزدیکی یک مار یا نردبان قرار دارد.
4.اقدام (Action)
اقدامها همان تصمیماتی هستند که عامل میگیرد. در این بازی، اقدامها شامل پرتاب تاس است که مقدار حرکت را تعیین میکند. برای مثال، اگر عامل تاس را بیندازد و عدد ۴ بیاید، به اندازهی ۴ خانه به جلو حرکت میکند.
5.پاداش (Reward)
پاداش مقدار ارزشی است که عامل پس از انجام یک اقدام دریافت میکند. در این مثال، اگر عامل روی خانهای بیفتد که او را به سمت نردبان بالا ببرد، پاداش مثبت میگیرد (مثلاً مثبت۱۰). اما اگر بر روی مار بیفتد و به خانههای پایینتر برگردد، پاداش منفی دریافت میکند (مثلاً منفی۱۰).
6.سیاست (Policy)
سیاست، همان استراتژی یا قوانینی است که عامل برای تصمیمگیری استفاده میکند. سیاست تعیین میکند که در هر وضعیت، عامل چه اقدامی انجام دهد. به عنوان مثال، سیاست ممکن است به این صورت باشد که اگر عامل به نزدیکی یک نردبان رسید، تلاش کند بر روی آن قرار گیرد.
7.تابع ارزش (Value Function)
تابع ارزش به عامل کمک میکند تا بفهمد هر وضعیت چقدر خوب است. به عبارت دیگر، هر چه یک وضعیت به هدف نزدیکتر باشد، ارزش بیشتری خواهد داشت. برای مثال، خانهی ۹۸ ارزش بیشتری نسبت به خانهی ۵۰ دارد، زیرا به خانهی ۱۰۰ نزدیکتر است.
8.تابع Q (Q-Function)
تابع Q شبیه به تابع ارزش است، اما به ترکیب وضعیت و اقدام توجه میکند. به عبارت دیگر، تابع Q به عامل میگوید که اگر در وضعیت فعلی یک اقدام خاص انجام دهد، چقدر احتمال دارد که به پاداش برسد. برای مثال، اگر عامل در خانهی ۱۰ باشد و تاس بیندازد، تابع Q تخمین میزند که آیا این اقدام به اندازهی کافی خوب است تا به خانههای بهتری برسد.

مفاهیم کلیدی در یادگیری تقویتی
1. فرآیند تصمیمگیری مارکوف (Markov Decision Process (MDP))
فرآیند تصمیمگیری مارکوف یک چارچوب ریاضی است که برای توصیف محیط در یادگیری تقویتی استفاده میشود. این چارچوب شامل مجموعهای از وضعیتها، اقدامها، احتمالات انتقال و پاداشهاست. فرآیند تصمیمگیری مارکوف فرض میکند که خاصیت مارکوف برقرار است ، به این معنی که وضعیت آینده تنها به وضعیت و اقدام کنونی بستگی دارد و به دنبالهای از رویدادهایی که قبل از آن اتفاق افتادهاند وابسته نیست.
2.اکتشاف (Exploration) و بهرهبرداری (Exploitation)
Exploration: به عاملی اشاره دارد که اقدامات جدیدی را برای کشف و جمعآوری اطلاعات بیشتر در مورد محیط انجام میدهد.
اکتشاف به معنی آزمایش گزینههای مختلف است. برای مثال ، فرض کنید یک ربات در حال یادگیری نحوه پیدا کردن غذا در یک اتاق است. در مرحله اکتشاف، ربات ممکن است به نقاط مختلف اتاق برود و مسیرهای متفاوتی را امتحان کند تا ببیند کدام یک به غذا میرسد.
Exploitation: به عامل اشاره دارد که اقداماتی را انتخاب می کند که می داند بر اساس دانش فعلی خود بالاترین پاداش را به همراه خواهد داشت.
بهرهبرداری به معنای استفاده از تجربیات قبلی برای گرفتن بهترین تصمیمات است. وقتی ربات مسیری را پیدا کند که به غذا میرسد ، در مرحلهی بهرهبرداری از همان مسیر استفاده میکند تا سریعتر و با اطمینان بیشتر به هدفش برسد.
به عبارت دیگر، ابتدا ربات چیزهای جدید را امتحان میکند (اکتشاف) و سپس از اطلاعاتی که به دست آورده برای تصمیمگیری بهتر در آینده استفاده میکند (بهرهبرداری). این دو مرحله به ربات کمک میکند تا در نهایت بهترین راه را برای رسیدن به هدفش یاد بگیرد.
یکی از مهمترین چالشهایی که به طور خاص در یادگیری تقویتی وجود دارد و سایر روشهای یادگیری با آن روبرو نیستند، نیاز به ایجاد تعادل بین اکتشاف و بهرهبرداری از تجربیات قبلی است.
چرا تعادل مهم است ؟

اگر فقط اکتشاف کنید و هرگز از اطلاعات قبلی استفاده نکنید، ممکن است زمان و منابع زیادی را صرف کنید و به نتایج ضعیفی دست یابید. از طرف دیگر، اگر تنها به استفاده از اطلاعات موجود بپردازید و هیچگاه چیزهای جدید را امتحان نکنید، ممکن است از گزینههای بهتر بیخبر بمانید و نتوانید پاداشهای بیشتری کسب کنید. بنابراین، تعادل میان اکتشاف و بهرهبرداری برای دستیابی به بهترین نتایج ضروری است .
کدام یک دید بیشتری به آینده دارد ؟
در یادگیری تقویتی، Exploitation بیشتر بر اساس تجربههای قبلی و پاداشهای به دست آمده است، یعنی این رویکرد به نوعی گذشتهنگر است. الگوریتم در این حالت از تصمیمهایی استفاده میکند که قبلاً پاداشهای خوبی به همراه داشتهاند. اما Exploration به آینده نگاه میکند؛ یعنی الگوریتم به جای تکیه بر تجربیات قبلی، به دنبال این است که اطلاعات بیشتری از محیط جمع کند تا در آینده تصمیمات بهتری بگیرد.
بنابراین، Exploration دید بیشتری به آینده دارد، زیرا به دنبال کشف احتمالات جدید و شاید بهتر است که ممکن است در آینده سودمند باشند.
3.سیگنال پاداش (Reward Signal)
سیگنال پاداش، بازخوردی است که عامل پس از انجام یک اقدام از محیط دریافت میکند. هدف عامل این است که پاداشهایی را که در طول زمان دریافت میکند به حداکثر برساند، و این امر فرآیند یادگیری او را هدایت میکند.
4.سیاست (Policy)
یک سیاست رفتار عامل را با تبدیل وضعیتها به اقدامات تعریف میکند. دو نوع سیاست وجود دارد:
سیاست قطعی: هر وضعیت را به یک اقدام خاص متصل میکند.
این نوع سیاست به هر وضعیت یک اقدام خاص را اختصاص میدهد. به عبارت دیگر، وقتی عامل در یک وضعیت خاص قرار دارد،همیشه یک اقدام مشخص را انتخاب میکند.
مثال: فرض کنید یک ربات در حال حرکت در یک اتاق است. اگر ربات در نزدیکی درب خروج قرار گیرد، طبق سیاست قطعی، همیشه از درب خارج میشود. بنابراین، در وضعیت «نزدیک درب خروج»، اقدام او «خروج از درب» است. این بدان معناست که او هیچ گزینه دیگری را در نظر نمیگیرد و همواره همین کار را انجام میدهد.
سیاست تصادفی: هر وضعیت را به یک توزیع احتمال بر روی اقدامات متصل میکند.
در این نوع سیاست، به هر وضعیت یک توزیع احتمال برای انتخاب اقدامات اختصاص داده میشود. به این معنا که عامل در هر وضعیت، با احتمالهای مختلف ممکن است اقدامهای متفاوتی را انتخاب کند.
مثال: فرض کنید یک ربات در یک اتاق با سه مسیر مختلف برای حرکت قرار دارد: راست، چپ و جلو. اگر ربات در وضعیت «نزدیک درب» قرار گیرد، ممکن است با ۵۰٪ احتمال به راست برود، با ۳۰٪ احتمال به چپ برود و با ۲۰٪ احتمال به جلو برود. در اینجا، هیچ تصمیم مشخصی وجود ندارد و انتخاب مسیر به صورت تصادفی و بر اساس این احتمالها انجام میشود.
5.تابع ارزش (Value Function)
تابع ارزش، پاداش تجمعی مورد انتظار را برای هر وضعیت تخمین میزند و نشان میدهد که یک وضعیت از نظر پاداشهای آینده چقدر ارزشمند است. این تابع به عامل کمک میکند تا اقداماتی را انتخاب کند که منجر به وضعیتهایی با پاداشهای مورد انتظار بالاتر شود.
6.تابع Q (Q-Function (Action-Value Function))
تابع Q، یا تابع ارزش اقدام، پاداش تجمعی مورد انتظار را برای انجام یک اقدام خاص در یک وضعیت مشخص و پیروی از سیاست بهینه تخمین میزند. این مفهوم در بسیاری از الگوریتمهای یادگیری تقویتی اهمیت زیادی دارد و به عامل کمک میکند تا تصمیمات بهتری را بر اساس ارزش اقدامات مختلف بگیرد.
تابع ارزش به دو نوع اصلی تقسیم میشود :
تابع ارزش وضعیت (V(s) یا Value Function) : این تابع ارزش هر وضعیت را بر اساس پاداشهایی که میتوان از آن وضعیت به دست آورد تخمین میزند.
تابع ارزش عمل (Q(s,a) یا Q-Function (Action-Value Function)) : این تابع ارزش یک عمل خاص در یک وضعیت خاص را محاسبه میکند و نشان میدهد که انجام آن عمل در آن وضعیت چه مقدار پاداش به ارمغان میآورد.
ترتیبی که هوشینو برای خواندن مطالب یادگیری تقویتی به شما پیشنهاد میکند:
1.یادگیری تقویتی بخش اول
10.الگوریتم Q-Learning بخش سوم
13. تفاوت بین Q-Learning و SARSA