




پیادهسازی الگوریتم SARSA (Implementing SARSA in Gymnasium’s Taxi-v3 Environment)
ما قصد داریم مراحل راهاندازی محیط، تعریف و پیادهسازی یک عامل یادگیری با الگوریتم SARSA، آموزش آن و تحلیل نتایج یادگیریاش را بررسی کنیم. هر یک از این مراحل کمک میکنند تا بهتر درک کنیم که SARSA، به عنوان یک الگوریتم درونسیاستی (on-policy)، چگونه سیاست خود را با توجه به اقداماتی که انجام میدهد و پاداشهایی که دریافت میکند، بهروزرسانی میکند. این در حالی است که الگوریتمهایی مثل Q-learning که برونسیاستی (off-policy) هستند، تأثیر سیاست فعلی بر نتایج را در نظر نمیگیرند.
گام1: راهاندازی و مقداردهی (Setup and Initialization)
ابتدا، با وارد کردن کتابخانههای ضروری شروع میکنیم و یک تابع رسم (plotting function) تعریف میکنیم که بعداً برای تجسم عملکرد عامل در طول اپیزودهای آموزشی از آن استفاده خواهیم کرد.
import gymnasium as gym
import numpy as np
from collections import defaultdict
import matplotlib.pyplot as plt
def plot_returns(returns):
plt.plot(np.arange(len(returns)), returns)
plt.title('Episode returns')
plt.xlabel('Episode')
plt.ylabel('Return')
plt.show()
گام2: تعریف محیط (Define the SARSA Agent)
در مرحله بعد، کلاس SARSAAgent را تعریف میکنیم. این عامل با مجموعهای از پارامترها اولیهسازی میشود که فرآیندهای یادگیری و تصمیمگیری آن را تعیین میکند. همچنین شامل متدهایی برای انتخاب اقدامات، بهروزرسانی مقادیر Q و تنظیم نرخ کاوش (exploration rate) است.
class SARSAAgent:
def __init__(self, env, learning_rate, initial_epsilon, epsilon_decay, final_epsilon, discount_factor=0.95):
self.env = env
self.learning_rate = learning_rate
self.discount_factor = discount_factor
self.epsilon = initial_epsilon
self.epsilon_decay = epsilon_decay
self.final_epsilon = final_epsilon
self.q_values = defaultdict(lambda: np.zeros(env.action_space.n))
def get_action(self, obs) -> int:
if np.random.rand() < self.epsilon:
return self.env.action_space.sample() # Explore
else:
return np.argmax(self.q_values[obs]) # Exploit
def update(self, obs, action, reward, terminated, next_obs, next_action):
if not terminated:
td_target = reward + self.discount_factor * self.q_values[next_obs][next_action]
td_error = td_target - self.q_values[obs][action]
self.q_values[obs][action] += self.learning_rate * td_error
def decay_epsilon(self):
self.epsilon = max(self.final_epsilon, self.epsilon - self.epsilon_decay)
گام3: آموزش عامل (Training the Agent)
با تعریف عامل SARSA، به آموزش آن در چندین اپیزود میپردازیم. تابع آموزش بر روی هر اپیزود تکرار میشود و به عامل این امکان را میدهد که با محیط تعامل کند، از اقدامات یاد بگیرد و به تدریج سیاست خود را بهبود بخشد.
def train_agent(agent, env, episodes, eval_interval=100):
rewards = []
for i in range(episodes):
obs, _ = env.reset()
terminated = truncated = False
total_reward = 0
while not terminated and not truncated:
action = agent.get_action(obs)
next_obs, reward, terminated, truncated, _ = env.step(action)
next_action = agent.get_action(next_obs)
agent.update(obs, action, reward, terminated, next_obs, next_action)
obs = next_obs
action = next_action
total_reward += reward
agent.decay_epsilon()
rewards.append(total_reward)
if i % eval_interval == 0 and i > 0:
avg_return = np.mean(rewards[max(0, i - eval_interval):i])
print(f"Episode {i} -> Average Return: {avg_return}")
return rewards
گام4: پیشرفت تجسم (Visualization of Learning Progress)
پس از آموزش، تجسم پیشرفت یادگیری مفید است. ما از تابع plot_returns برای نمایش بازدهها در هر اپیزود استفاده میکنیم که بینشهایی در مورد اثربخشی رژیم آموزشی ما ارائه میدهد.
env = gym.make('Taxi-v3', render_mode='ansi')
episodes = 20000
learning_rate = 0.5
initial_epsilon = 1
final_epsilon = 0
epsilon_decay = (final_epsilon - initial_epsilon) / (episodes / 2)
agent = SARSAAgent(env, learning_rate, initial_epsilon, epsilon_decay, final_epsilon)
returns = train_agent(agent, env, episodes)
plot_returns(returns)
گام5: اجرای عامل آموزش دیده (Running the Trained Agent)
در نهایت، برای مشاهده عملکرد عامل آموزشدیدهمان، میتوانیم آن را در محیط اجرا کنیم. در این مرحله، نرخ کاوش (exploration rate) را کاهش میدهیم زیرا عامل باید سیاست تقریباً بهینهای را یاد گرفته باشد.
def run_agent(agent, env):
agent.epsilon = 0 # No need to keep exploring
obs, _ = env.reset()
env.render()
terminated = truncated = False
while not terminated and not truncated:
action = agent.get_action(obs)
next_obs, _, terminated, truncated, _ = env.step(action)
print(env.render())
خروجی:
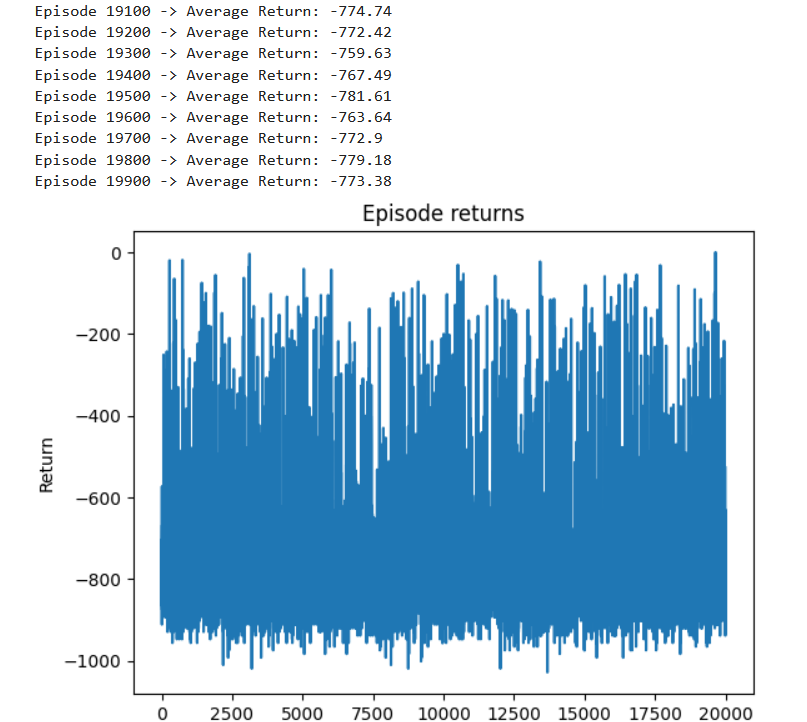
توضیح خروجی:
خروجی کد شامل دو بخش اصلی است:
- نمودار پیشرفت آموزش و بازدههای اپیزود (Training Progress and Episode Returns Plot):
- در طول آموزش، عملکرد عامل SARSA بهصورت دورهای ارزیابی میشود و میانگین بازده در هر eval_interval اپیزود چاپ میشود.
- پس از آموزش، نموداری از بازدههای اپیزود در طول زمان نمایش داده میشود که نشان میدهد عملکرد عامل چگونه با یادگیری از اپیزودهای بیشتر تغییر میکند.
- نمایش رفتار عامل (Agent’s Behavior Demonstration):
- پس از آموزش، تابع run_agent رفتار عامل را در محیط ” Taxi-v3″ نشان میدهد. وضعیت محیط در هر مرحله در کنسول چاپ میشود و تصمیمات و حرکات عامل را نمایش میدهد.
نمودار بازده در برابر اپیزود (Returns vs Episode Plot): در پایان آموزش، تابع plot_returns نموداری ایجاد میکند که بازده کل برای هر اپیزود را نشان میدهد. محور x شماره اپیزود و محور y بازده (پاداش کل) آن اپیزود را نمایش میدهد. این نمودار به تجسم منحنی یادگیری عامل کمک میکند و روندهایی مانند بهبود، ثبات یا نوسانات در عملکرد را نشان میدهد.
نمایش خروجی شبکه (Demonstration of the Output Grid:):
- سری نمودارها نشان میدهد که چگونه عامل در شبکه حرکت میکند، بهطوریکه هر مرحله نمایانگر یک حرکت یا چرخش است.
- مسیر عامل با تغییرات حرکتی و جهتگیری آن تعریف میشود و هدف آن رسیدن به یک نقطه هدف (G) یا نقاط مهم دیگر (R و B) در شبکه است.
- جهتگیریهای خاص (شمال، شرق و غیره) برای درک استراتژی یا الگوریتم عامل در حرکت در شبکه بسیار حائز اهمیت هستند.
نتیجهگیری (Conclusion)
پیادهسازی یک عامل SARSA در محیط Taxi-v3 از Gymnasium یک رویکرد عملی برای درک الگوریتمهای یادگیری تقویتی درونسیاستی ارائه میدهد. با راهاندازی محیط، تعریف عامل، آموزش و تجزیه و تحلیل پیشرفت آن، بینشهای ارزشمندی در مورد چگونگی بهروزرسانی سیاستهای SARSA بر اساس اقدامات فعلی و نتایج آنها بهدست میآوریم.
ترتیبی که هوشینو برای خواندن مطالب یادگیری تقویتی به شما پیشنهاد میکند:
10.الگوریتم Q-Learning بخش سوم
12.الگوریتم SARSA-بخش دوم