




کاربردهای زنجیره مارکوف در الگوریتمها
1.الگوریتم Viterbi
2.الگوریتم Forward-Backward
3.الگوریتم PageRank
4.الگوریتم Monte Carlo
5.الگوریتم Q-learning
6.الگوریتم POMDP (Partially Observable Markov Decision Process)
7.الگوریتم Hidden Markov Model (HMM)
8.الگوریتم Reinforcement Learning
9.الگوریتم Dynamic Programming
1.الگوریتم Viterbi
کاربرد زنجیره مارکوف:
الگوریتم Viterbi بهویژه در مدلهای مارکوف پنهان (HMM) استفاده میشود تا بهترین دنبالهای از حالات پنهان را پیدا کند که احتمال مشاهده یک دنباله خاص از نشانهها را حداکثر میکند. به عبارت دیگر، این الگوریتم تلاش میکند بفهمد چه اتفاقاتی در پسزمینه (حالات پنهان) باعث ایجاد مشاهدات (صداها، کلمات و غیره) شده است.
مثال: فرض کنید در حال تحلیل گفتار یک فرد هستید. هر بار که فرد صحبت میکند، ممکن است او در یکی از چند حالت قرار داشته باشد: خواب، کار یا تفریح. با استفاده از الگوریتم Viterbi، میتوانید به بهترین نحو تعیین کنید که فرد در هر لحظه کدام وضعیت را تجربه میکند، بر اساس نشانههایی که از او دریافت میکنید (مانند اینکه او چه کلماتی میگوید).
2.الگوریتم Forward-Backward
کاربرد زنجیره مارکوف:
این الگوریتم بهمنظور محاسبه احتمال یک دنباله از نشانهها در یک مدل مارکوف پنهان (HMM) استفاده میشود. با استفاده از این الگوریتم، میتوانیم بفهمیم که چگونه یک مدل به مشاهدات رسیده است و چه احتمالی برای هر حالت وجود دارد.
مثال: فرض کنید شما در حال تشخیص احساسات یک شخص هستید. با گوش دادن به صداهای او (نشانهها) و استفاده از Forward-Backward، میتوانید محاسبه کنید که چه احساسی (شادی، غم و …) احتمال بیشتری دارد با توجه به نشانههای خاصی که شنیدهاید.
3.الگوریتم PageRank گوگل:
کاربرد زنجیره مارکوف:
PageRank بهطور خاص برای رتبهبندی صفحات وب بر اساس اهمیت آنها استفاده میشود. این الگوریتم به عنوان یک زنجیره مارکوف مدل میکند که چگونه کاربران از یک صفحه به صفحه دیگر میروند. اگر یک صفحه وب به چندین صفحه دیگر لینک داده باشد، این صفحات دیگر نیز به آن صفحه اهمیت بیشتری میدهند.

این تصویر الگوریتم PageRank گوگل را بهصورت شبکهای از گرهها و اتصالات نمایش میدهد که سایتها و ارتباطات بین آنها را از نظر اهمیت رتبهبندی نشان میدهد.
مثال: تصور کنید وبسایتی دارید که به چندین وبسایت دیگر لینک داده است. با استفاده از PageRank، میتوانید بفهمید که آیا وبسایت شما به اندازه کافی مهم است یا خیر، بر اساس اینکه چه تعداد صفحه به آن لینک دادهاند و این صفحات چقدر معتبر هستند.
4.الگوریتم Monte Carlo
کاربرد زنجیره مارکوف:
روشهای Monte Carlo از زنجیرههای مارکوف برای تولید نمونههای تصادفی از یک توزیع استفاده میکنند. این روشها میتوانند برای برآورد مقادیر مورد نیاز در مسائل پیچیده و در شرایط عدم قطعیت استفاده شوند.
مثال: فرض کنید میخواهید مساحت یک شکل پیچیده را محاسبه کنید. میتوانید از زنجیره مارکوف برای تولید نقاط تصادفی در یک مستطیل حاوی آن شکل استفاده کنید و سپس با شمارش تعداد نقاطی که درون شکل قرار دارند، مساحت آن را برآورد کنید.
5.الگوریتم Q-learning
کاربرد زنجیره مارکوف:
Q-learning یک روش یادگیری تقویتی است که به ماشینها یاد میدهد چگونه بهترین تصمیمات را در یک محیط مشخص بگیرند. این الگوریتم بر اساس فرایند تصمیمگیری مارکوف (MDP) کار میکند و به ماشینها اجازه میدهد از تجربیاتشان بیاموزند.
مثال: فرض کنید یک ربات در حال یادگیری نحوه پیمایش در یک اتاق است. این ربات با استفاده از Q-learning یاد میگیرد که هر بار که حرکتی انجام میدهد، چه پاداشی دریافت میکند و میتواند بهترین راه را برای رسیدن به هدفش پیدا کند. به این ترتیب، ربات به تدریج بهتر و بهتر میشود.
6.الگوریتم POMDP (Partially Observable Markov Decision Process)
در فرایند تصمیمگیری مارکوف جزئی (POMDP)، عامل نمیتواند به طور کامل حالت سیستم را مشاهده کند. ؛ یعنی حالتها بهصورت کامل برای عامل قابل مشاهده نیستند. در این موارد از تصمیمگیری مارکوف جزئی استفاده میشود. این مدل پیچیدهتر است و علاوه بر حالتها، شامل یک تابع باور (belief) نیز میشود که احتمال حضور در هر حالت را با توجه به مشاهدات عامل تخمین میزند.
فرض کنید شما در یک هزارتوی تاریک هستید و نمیتوانید بهطور دقیق ببینید در کدام اتاق هستید، اما از طریق نشانههای محیطی (مثل صدا یا دما) بهطور تقریبی میتوانید بفهمید در کدام اتاق هستید. اینجا یک “تابع باور” وجود دارد که احتمالات حضور شما در هر اتاق را بهروز میکند.
کاربرد زنجیره مارکوف:
فرایند تصمیمگیری مارکوف جزئی یک مدل تعمیمیافته از فرایند تصمیمگیری مارکوف است که در آن اطلاعات برخی از حالتها پنهان است. این الگوریتم بهمنظور تصمیمگیری در شرایط عدم قطعیت و در زمانی که نمیتوانیم وضعیت دقیق محیط را مشاهده کنیم، استفاده میشود.
مثال: تصور کنید که یک ربات در یک اتاق تاریک حرکت میکند و نمیتواند ببیند. فرایند تصمیمگیری مارکوف جزئی به ربات کمک میکند با استفاده از اطلاعات محدود و گذشته خود، تصمیمات بهتری بگیرد و هدفش را پیدا کند.
7.الگوریتم Hidden Markov Model (HMM)
کاربرد زنجیره مارکوف:
مدل مارکوف پنهان یکی از ابزارهای قدرتمند برای تجزیه و تحلیل دنبالههای زمانی است. این الگوریتم بهطور خاص برای پیشبینی و تشخیص وضعیتهای پنهان بر اساس نشانههای مشهود استفاده میشود.
مثال: در تشخیص گفتار، مدل مارکوف پنهان میتواند به ما کمک کند تا بفهمیم فرد در حال بیان چه کلماتی است، با توجه به صداهایی که ضبط کردهایم. این مدل فرض میکند که وضعیت فعلی (کلمه) تنها به وضعیت قبلی وابسته است و از این رو میتواند دقت بالایی در تشخیص گفتار داشته باشد.
8.الگوریتم Reinforcement Learning
کاربرد زنجیره مارکوف:
یادگیری تقویتی بر اساس فرایند تصمیمگیری مارکوف و زنجیرههای مارکوف کار میکند و به ماشینها این امکان را میدهد تا با یادگیری از تجربیات خود، اقداماتی انجام دهند که بیشترین پاداش را برای آنها به ارمغان بیاورد.
مثال: تصور کنید که یک بازیکن در یک بازی ویدئویی قرار دارد. او باید با یادگیری از اقداماتی که در بازی انجام میدهد، بهترین حرکات را پیدا کند. یادگیری تقویتی به بازیکن کمک میکند تا با یادگیری از تجربیاتش، نقاط قوت و ضعف خود را شناسایی کند و به تدریج بهتر شود.
9.الگوریتم Dynamic Programming
کاربرد زنجیره مارکوف:
از روشهای برنامهریزی پویا برای حل مسائل بهینهسازی و فرایند تصمیم گیری مارکوف استفاده میشود. این الگوریتمها با شکستن یک مشکل بزرگ به زیرمسائل کوچکتر، کارایی بیشتری را به ارمغان میآورند.
مثال: فرض کنید میخواهید هزینه کمترین مسیر را از یک نقطه به نقطه دیگر در یک نقشه محاسبه کنید. با استفاده از برنامهریزی پویا، میتوانید از زنجیره مارکوف برای محاسبه هزینه هر مسیر استفاده کنید و بهترین مسیر را پیدا کنید.
زمانبندی و فرایند تصمیم گیری مارکوف با زمان گسسته یا پیوسته
در بسیاری از فرایند تصمیم گیری مارکوف زمان بهصورت گسسته در نظر گرفته میشود؛ یعنی در هر لحظه تنها یک عمل انجام میشود و سپس سیستم به حالت بعدی منتقل میشود. اما در برخی مسائل، زمان به صورت پیوسته است و سیستم میتواند در هر لحظه از زمان عمل کند. این مدلها پیچیدهتر هستند و به فرایند تصمیم گیری مارکوف با زمان پیوسته معروفاند.
در MDPهای محدود، علاوه بر تلاش برای بهینهسازی پاداش، باید به محدودیتهایی مثل منابع انرژی یا زمان نیز توجه کنید.
مثال: فرض کنید یک ربات دارید که باید وظایف مختلفی را انجام دهد، اما تنها باتری محدودی دارد. در اینجا علاوه بر اینکه میخواهید وظایف را به بهترین نحو انجام دهید، باید مطمئن شوید که ربات قبل از خالی شدن باتری به اتمام کارهایش میرسد.
چگونه به مرحله همگرا شدن میرسیم ؟
در زنجیرههای مارکوف، هدف شما این است که پس از طی یک تعداد معینی از مراحل، توزیع احتمالات حالتها به یک توزیع ثابت یا پایدار (که به آن توزیع پایدار یا توزیع ایستا میگویند) همگرا شود. این توزیع پایدار، زمانی به دست میآید که زنجیره به حالت تعادل برسد و دیگر تغییرات قابل توجهی در توزیع احتمالات حالتها رخ ندهد.
مراحل رسیدن به توزیع پایدار:
1.نوشتن ماتریس انتقال احتمالات :
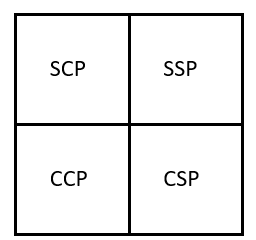
ابتدا باید ماتریس انتقال احتمالات را تعریف کنیم. فرض کنید که دو حالت داریم:
- حالت آفتابی (S)
- حالت ابری (C)
- ماتریس انتقال احتمالات P به صورت روبرو است :
- SSP یعنی احتمال اینکه فردا آفتابی باشد ، اگر امروز آفتابی باشد.
- SCP یعنی احتمال اینکه فردا ابری باشد ، اگر امروز آفتابی باشد.
- CSP یعنی احتمال اینکه فردا آفتابی باشد ، اگر امروز ابری باشد.
- CCP یعنی احتمال اینکه ابری آفتابی باشد ، اگر امروز ابری باشد.
2.یافتن توزیع پایدار :
- توزیع پایدار، توزیعی است که با گذر زمان تغییر نمیکند. برای یافتن این توزیع، باید برداری را پیدا کنیم که وقتی با ماتریس انتقال P ضرب میشود، خودش را تولید کند:
- این معادله به این معناست که توزیع جدید همانند توزیع قبلی است و هیچ تغییر معنیداری در توزیع ایجاد نمیشود.
3.نوشتن معادلات :
- از معادله فوق، معادلات زیر به دست میآید:
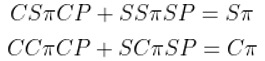
4.شرط نرمالسازی :
- چون مجموع احتمالات باید برابر با 1 باشد، یک شرط نرمالسازی داریم:
![]()
5.حل دستگاه معادلات :
- حالا این معادلات را حل میکنیم تا مقادیر و (توزیع پایدار) را به دست آوریم.
مثال عملی :
فرض کنید که ماتریس انتقال به شکل زیر باشد:

1.نوشتن معادلات توزیع پایدار :
- معادلات زیر را داریم:
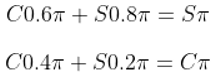
2.حل معادله اول :
- از معادله اول مینویسیم:
![]()
- این را حل میکنیم :
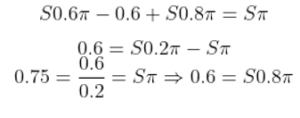
3.استفاده از شرط نرمالسازی :
- با استفاده از شرط نرمالسازی:
![]()
نتیجهگیری
توزیع پایدار برای این زنجیره مارکوف به صورت زیر است:
0.75 =![]() (احتمال آفتابی)
(احتمال آفتابی)
0.25 =![]() (احتمال ابری)
(احتمال ابری)
ترتیبی که هوشینو برای خواندن مطالب یادگیری تقویتی به شما پیشنهاد میکند:
7.زنجیره مارکوف بخش چهارم